A distancia
Curso de Big Data
Horario flexible a tiempo parcial que se adapta a tu estilo de vida

TripleTen está incluido por Forbes en "5 bootcamps de codificación a tener en cuenta"
El nuevo informe de TripleTen revela las tendencias de contratación de los profesionales que se orientan hacia la tecnología

TripleTen es el mejor bootcamp de Ingeniería de Software para 2024




Big Data se refiere al procesamiento y análisis de volúmenes de datos tan grandes y complejos, que superan las capacidades de las herramientas tradicionales. Su importancia radica en que permite a las empresas descubrir patrones ocultos, optimizar operaciones y anticipar tendencias.
🔷 Data Growth: la creación de datos crece un 25% anual a nivel global.
🔷 Decision-making: empresas que aprovechan Big Data mejoran en 5ˣ la toma de decisiones estratégicas.
A diferencia del análisis tradicional, el Big Data trabaja, en tiempo real y a escala masiva, tanto con datos estructurados (bases relacionales) como no estructurados (redes sociales, logs, imágenes o texto libre).
Aprender Big Data implica prepararse para operar grandes cantidades de información en este nuevo paradigma de velocidad, variedad y volumen.
Esto es lo que puedes ganar como especialista en Big Data
Estas son las opiniones de algunos de nuestros más de 6,000+ graduados
Ahora: PM de análisis de datos y Machine Learning
“No importa lo que hayas hecho haste ahora en tu vida, siempre tienes la oportunidad de hacer algo nuevo, de reinventarte y lograr el futuro que quieras lograr.”

Ahora: QA Engineer
“Soy una orgullosa graduada de Tripleten. Puedo constatar el valor del contenido que ofrece el Bootcamp, ya que cubre la teoría y la práctica de manera integral.”

Ahora: Data Engineer Intern-Konfio
“Me ha impactado demasiado, ya que para mi es de lo mejor el poder actualmente estudar 2 carreras al mismo tiempo y tener el trabajo en mi area o bueno un area cercana”

Ahora: Jr Data Instructor en TripleTen
“Lo primero que destaca de TripleTen es su equipo docente altamente calificado y comprometido. Los profesores no solo son expertos en sus campos respectivos, sino que también tienen una pasión innata por guiar y nutrir a sus estudiantes.”

Ahora: Instructor en Data Science y Data Analyst
“El curso me dio un amplio conocimiento del tema y lo mejor fue que me permitió aprender directamente de expertos, adquiriendo conocimientos de primera mano.”

Ahora: Arkon Data, Data Processes Operator
“Me ayudó a cambiar de carrera y encontrar mi verdadera vocación.”

Ahora: Analista de Producto
“El bootcamp de TripleTen ha tenido un impacto transformador en mi vida. Gracias a TripleTen, no solo adquirí nuevas competencias, sino también una mayor claridad sobre mis objetivos profesionales y cómo alcanzarlos.”

Ahora: Data Analytics Internship, MR MARVIS
“Ha sido la principal herramienta para mi cambio de carrera. La plataforma tiene todo organizado de una manera útil y bien explicada. Tienes la posibilidad de hacer ejercicios y proyectos que serán revisados.”

Ahora: Data Analyst, Endava
“Me permitió organizar mi ruta de aprendizaje y estructurar el conocimiento que había adquirido en otros medios y en mi experiencia laboral en el ámbito de los datos. Me brindó visibilidad y creó oportunidades de crecimiento, siendo clave para encaminar mi carrera.”

Ahora: Outlier, AI Training
“Me permitió adquirir las herramientas necesarias para iniciar una trayectoria en un campo diferente al que conocía. Ahora cuento con un trabajo remoto y flexibilidad de tiempo para trabajar a mis propios términos.”

Ahora: Analista de datos
“Me dio mucha disciplina y me ayudó a encontrar un trabajo bien remunerado.”

Ahora: Associate Data Analyst
“Yo de formación soysocióloga, y las oportunidades laborales no eran muchas y no estaban bien pagadas, y creo que esto me abrió muchas puertas, el trabajo que conseguí es muy bueno, así que estoy muy agradecida por eso.”







Ahora: Data Scientist
“Puedes empezar de nuevo sin importar la edad.”

Ahora: Jato Dynamics, Data Specialist
Me ayudo a capacitarme con las herramientas necesarias para entrar en la industria de los datos

¿Qué aprenderás en el curso de Big Data de TripleTen?
Al aprender Big Data, deberás prepararte para trabajar con las herramientas más poderosas de la industria y llevar tus conocimientos de datos al siguiente nivel. Este módulo del programa de Científico de Datos está diseñado para quienes buscan dominar el tratamiento de datos a gran escala y resolver desafíos reales en entornos empresariales.
| Tecnologías modernas de Big Data | |
| ‣ Hadoop y su ecosistema | Aprende a manejar almacenamiento distribuido y procesamiento por lotes. Herramienta esencial para Data Science. |
| ‣ Apache Spark | Ejecuta análisis de alto rendimiento y procesamiento en memoria. |
| ‣ Bases de datos NoSQL | Trabaja con datos estructurados y no estructurados en MongoDB y Cassandra |
| ‣ Cloud platforms | Desarrolla soluciones en AWS, Google Cloud y Azure, como lo hacen las grandes empresas. |
| ‣ Streaming en tiempo real | Usa Apache Kafka para gestionar flujos de datos en vivo. |
Estas son las habilidades estratégicas que desarrollarás:
🔶 Procesar y analizar conjuntos de datos masivos con enfoque empresarial.
🔶 Diseñar arquitecturas escalables en entornos distribuidos.
🔶 Construir pipelines de datos eficientes en plataformas cloud.
🔶 Tomar decisiones basadas en analítica avanzada y visualizaciones UX/UI.
Al completar el programa, tendrás los estudios y las competencias necesarias para asumir roles especializados en big data, desde ingeniero de datos hasta arquitecto de soluciones empresariales. Tu perfil estará alineado con lo que buscan las organizaciones que operan con datos a gran escala.
¿Este curso es para ti?
Sí, si tienes conocimientos básicos de programación o estadística y buscas especializarte en tecnologías avanzadas. Esta formación en Big Data es ideal para analistas de datos, ingenieros junior, recién graduados o profesionales que quieren transicionar hacia roles técnicos en datos.
Aprender ciencia de datos te ayudará en tu proceso de convertirte en Data Scientist de gran nivel profesional. Este curso de Big Data es remoto y online, lo que te permitirá aprender a tu ritmo, conocer a estudiantes de todo el mundo y crecer profesionalmente.
¿Por qué elegir TripleTen para tu especialización en Big Data?
Mientras que muchos cursos solo cubren conceptos generales o se quedan en teoría, TripleTen ofrece formación práctica para aprender Big Data con datasets empresariales reales.
Diferenciación competitiva de nuestro curso de Big Data
| Aspecto | TripleTen | Cursos generales de datos | Cursos teóricos de Big Data |
| Enfoque | ⚡️Big Data empresarial | ✔ Análisis de pequeños datasets | ⚠️Conceptos teóricos |
| Escalabilidad | ⚡️Computación distribuida | ✔ Procesamiento en un solo equipo | ⚠️Cursos sin práctica en escala real |
| Tecnologías | ⚡️Hadoop, Spark, NoSQL, Cloud | ✔ SQL y herramientas básicas | ⚠️Tecnologías obsoletas |
| Soluciones | ⚡️Cloud-native | ✔ Cursos on-premise de ciencias de datos | ⚠️Modelos abstractos |
| Práctica | ⚡️Proyectos con datos masivos | ⚠️Ejercicios simples | ✔️ Ejemplos académicos |
| Herramientas | ⚡️Estándar de la industria | ⚠️Software genérico | ⚠️ Teoría sin stack actual |
| Carrera | ⚡️Roles de Big Data reales | ⚠️Formación generalista | ✔️ Enfoque académico |
Sprint 1 Python básico
2 semanas
Capítulo 1. Introducción a tu futura profesión
Capítulo 2. Variables, tipos de datos y operaciones aritméticas
Capítulo 3. Strings
Capítulo 4. Listas
Sprint 2 Python básico (continuación)
2 semanas
Capítulo 1. Bucles
Capítulo 2. Sentencias condicionales
Capítulo 3. Diccionarios
Capítulo 4. Funciones
Sprint 3 Manipulación de datos (Data Wrangling)
2 semanas
Capítulo 1. La librería Pandas
Capítulo 2. Leer y visualizar datos
Capítulo 3. Trabajar con valores duplicados y ausentes
Capítulo 4. Filtrado de datos
Sprint 4 Manipulación de datos (Data Wrangling) (continuación)
2 semanas
Capítulo 1. Tipos de datos
Capítulo 2. Ingeniería de características
Capítulo 3. Transformación de datos
Capítulo 4. Visualización de datos
Sprint 5 Análisis estadístico de datos
3 semanas
Capítulo 1. Estadística descriptiva
Capítulo 2. Teoría de la probabilidad
Capítulo 3. Prueba de hipótesis
Sprint 6 Proyecto del módulo 1
1 semana
Sprint 7 Herramientas de desarrollo de software
3 semanas
Capítulo 1. Introducción a la línea de comandos
Capítulo 2. Entornos de desarrollo
Capítulo 3. Git y GitHub
Capítulo 4. Python intermedio
Capítulo 5. Entorno de desarrollo individual
Sprint 8 Recopilación y almacenamiento de datos (SQL)
2 semanas
Capítulo 1. Recuperar datos de recursos en línea
Capítulo 2. SQL como herramienta para trabajar con datos
Capítulo 3. Funciones avanzadas de SQL para analistas
Capítulo 4. Relaciones entre tablas
Capítulo 5. Habilidades sociales (Soft skills)
Sprint 9 Introducción al machine learning
2 semanas
Capítulo 1. Entrenar tu primer modelo
Capítulo 2. Calidad del modelo
Capítulo 3. Mejora del modelo
Capítulo 4. Pasar a la regresión
Sprint 10 Aprendizaje supervisado
2 semanas
Capítulo 1. Codificación y estandarización de datos
Capítulo 2. Métricas de clasificación
Capítulo 3. Clasificación desbalanceada
Capítulo 4. Métricas de regresión
Capítulo 5. Habilidades sociales (Soft skills)
Sprint 11 Aprendizaje automático en negocios
2 semanas
Capítulo 1. Métricas de negocio
Capítulo 2. Implementar una nueva funcionalidad
Capítulo 3. Recopilación de datos
Capítulo 4. Habilidades sociales (Soft skills)
Sprint 12 Proyecto del módulo 2
1 semana
Sprint 13 Álgebra lineal
2 semanas
Capítulo 1. Vectores y operaciones vectoriales
Capítulo 2. Distancia entre vectores
Capítulo 3. Matrices y operaciones matriciales
Capítulo 4. Regresión lineal desde el interior
Sprint 14 Métodos numéricos
2 semanas
Capítulo 1. Análisis de algoritmos
Capítulo 2. Descenso de gradiente
Capítulo 3. Entrenamiento de descenso de gradiente
Capítulo 4. Potenciación del gradiente
Capítulo 5. Habilidades sociales (Soft skills)
Sprint 15 Series temporales
2 semanas
Capítulo 1. Análisis de series temporales
Capítulo 2. Pronóstico de series temporales
Sprint 16 Aprendizaje automático para textos
2 semanas
Capítulo 1. Vectorización de textos
Capítulo 2. Representaciones del lenguaje
Sprint 17 Visión artificial
2 semanas
Capítulo 1. Redes totalmente conectadas
Capítulo 2. Redes neuronales convolucionales
Capítulo 3. Habilidades sociales (Soft skills)
Sprint 18 Aprendizaje no supervisado
1 semana
Capítulo 1. Clustering
Capítulo 2. Detección de anomalías
Sprint 19 Proyecto final
2 semanas
Expertos senior que te apoyarán en cada paso de este curso de Big Data y Data Science
3+ años de experiencia
PROTECCIÓN S.A., Sempli

12 años de experiencia
Reysi de La Laguna, Duale Hochschule Baden-Württemberg (DHBW) Mosbach

20 años de experiencia
Entel, Universidad de Chile, Penta Analytics

4+ años de experiencia
eSage Group, Grupo Monge, Aunasoft S.A., Bixlabs

6 años de experiencia
Metropolitan Touring, Universidad de los Hemisferios, Prex Technologies

10+ años de experiencia
Thoughtworks, Walmart Chile

5 años de experiencia
PepsiCo, Arkon Data, Scale AI, Apziva

5,5 años de experiencia
Le Wagon, National Laboratory of Public Policies, CLEAR-LAC, University of Cartagena

2,5 años de experiencia
Unilever, Embrapa, Centro Internacional de Física

Beneficios del programa de Big Data
El curso en Big Data de TripleTen no es solo un curso técnico para aprender big data: es una vía directa hacia una carrera especializada, bien remunerada y con proyección internacional. Está diseñado para que desarrolles habilidades aplicables desde el primer día en roles altamente demandados por empresas de todos los sectores.
Ventajas profesionales
🔷Salario potencial competitivo: los perfiles con experiencia en ciencia de datos ganan en promedio un 30% más que los analistas de datos tradicionales, según empresas como Glassdoor y Indeed (2024).
🔷Especialización estratégica: este curso te prepara para ocupar posiciones como Big Data Engineer, Data Architect, Cloud Data Engineer o Big Data Analyst, todas con alta demanda tanto en América Latina como en mercados globales.
🔷Ruta de crecimiento definida: la formación técnica y práctica que obtendrás te permite avanzar con claridad hacia cargos senior, arquitecturas de datos complejas y liderazgo en proyectos de transformación digital.
Además, el programa está 100% alineado con las tecnologías que cambian el panorama del análisis de datos. No aprenderás conceptos en el vacío, sino que resolverás problemas reales con herramientas que ya se usan en empresas como Amazon, Netflix o Mercado Libre.
Credibilidad y confianza para aprender Big Data
🔶Formación aplicada con herramientas líderes: trabajarás con Hadoop, Spark, bases NoSQL, Kafka y plataformas como AWS, Google Cloud y Azure. Son las mismas que utilizan las empresas Fortune 500 para gestionar datos masivos y tomar decisiones en tiempo real.
🔶Proyectos con datasets reales: nada de ejercicios simulados. Desde las primeras semanas, aplicarás lo aprendido en escenarios empresariales reales, con volúmenes de datos comparables a los de industrias como la banca, el e-commerce o logística.
🔶Preparación para certificaciones cloud: si buscas una certificación formal, este curso te brinda los conocimientos para presentar exámenes de especialización en AWS Certified Big Data – Specialty, Google Cloud Professional Data Engineer o Azure Data Fundamentals.
Tu CV después de TripleTen

Data Scientist


GitHub
Educación
Ene-Sept 2025
Sueldo esperado
Habilidades duras

Python

Jupyter Notebook

Command Line Interface (CLI)

Git

GitHub

Pandas

Matplotlib

Seaborn

Plotly

SQL

Scikit-learn

Keras

CatBoost

LightGBM

XGBoost
nltk
Soft Skills
Capacidad para trabajar en equipo
Independencia
Comunicación proactiva sobre problemas
Capacidad para hacer preguntas adecuadas al asignarse tareas
Presentación adecuada de resultados
Formulación de ideas y posturas
Pensamiento sistemático y crítico
Proyectos
+420 horas de codificación en Python, SQL

Consigue el trabajo a los 6 meses de graduarte o te devolvemos el dinero
Nuestros graduados trabajan en startups locales y gigantes internacionales





¿Dónde se usa Big Data? Aplicaciones en industrias reales con alto impacto
El Big Data se ha convertido en una tecnología estratégica para transformar la manera en que operan las organizaciones. Su capacidad para procesar, almacenar y analizar conjuntos masivos de datos en tiempo real abre oportunidades en casi todos los sectores económicos.
Más allá de ser una tendencia, es una disciplina que impulsa la innovación, optimiza procesos y genera valor en empresas que toman decisiones basadas en datos. A continuación, exploramos cómo se aplican las tecnologías de Data Science en distintos sectores clave:
Salud y biotecnología
En el sector salud, el uso de Data Science ha revolucionado la atención médica y la investigación clínica. A través del análisis de historiales médicos electrónicos (EHR), imágenes diagnósticas, datos genómicos y registros de pacientes, los hospitales y centros de investigación pueden:
🔷 Mejorar la precisión diagnóstica con modelos de inteligencia artificial.
🔷 Detectar patrones de enfermedades antes de que se manifiesten clínicamente.
🔷 Reducir costos operativos mediante la optimización de recursos hospitalarios.
🔷 Acelerar el desarrollo de nuevos medicamentos gracias al análisis de datos de ensayos clínicos.
Ejemplo: el uso de Hadoop y Apache Spark en grandes hospitales permite procesar millones de registros médicos para identificar factores de riesgo en enfermedades crónicas como diabetes o hipertensión.
Finanzas y banca
Big Data permite a bancos, aseguradoras y fintechs analizar millones de transacciones en tiempo real. Este procesamiento masivo de datos estructurados y no estructurados ayuda a:
🔶 Prevenir fraudes financieros a través de detección de anomalías con Machine Learning.
🔶 Evaluar riesgos de crédito en segundos gracias a modelos predictivos.
🔶 Personalizar productos financieros con base en el comportamiento del usuario.
🔶 Cumplir con normativas de transparencia y auditoría mediante trazabilidad de datos.
Ejemplo: JPMorgan Chase utiliza arquitecturas distribuidas basadas en Apache Kafka y Spark para el monitoreo en tiempo real de fraudes y patrones de lavado de dinero.
Retail y comercio electrónico
En retail y e-commerce, Big Data permite capturar y analizar datos de comportamiento de usuario, historial de compras, logística, y redes sociales para:
🔷 Diseñar estrategias de pricing dinámico basadas en demanda y competencia.
🔷 Personalizar experiencias de usuario con motores de recomendación.
🔷 Optimizar el inventario con análisis predictivo de ventas.
🔷 Automatizar campañas de marketing multicanal en tiempo real.
🔷 PLUS: Desarrollo web para Big Data
Ejemplo: Walmart analiza petabytes de datos diarios en plataformas cloud (como AWS) para ajustar precios, gestionar inventarios globales y segmentar audiencias con alta precisión.
Logística, movilidad y transporte
En esta industria, Big Data se utiliza para planificar rutas, administrar cadenas de suministro, prever fallos mecánicos y optimizar la experiencia del cliente. Algunas aplicaciones clave incluyen:
🔶 Ruteo dinámico de vehículos con algoritmos en tiempo real.
🔶 Gestión predictiva de mantenimiento con IoT y análisis histórico.
🔶 Optimización de centros de distribución mediante simulaciones basadas en datos.
🔶 Integración de sistemas ERP y plataformas de seguimiento logístico con flujos de datos en streaming.
Ejemplo: UPS utiliza plataformas de Big Data como Hadoop para optimizar rutas de entrega, ahorrando millones de galones de combustible al año.
Tecnología y telecomunicaciones
Con millones de usuarios conectados simultáneamente, las tel-cos generan enormes volúmenes de datos. Big Data permite:
🔷 Monitorear calidad de red y prevenir interrupciones.
🔷 Segmentar usuarios y lanzar campañas personalizadas a los clientes.
🔷 Predecir churn (fuga de clientes) con modelos estadísticos.
🔷 Mejorar el rendimiento de infraestructura a través de análisis de tráfico.
Ejemplo: Telefónica procesa datos en clústeres distribuidos para mejorar la cobertura, ajustar precios y gestionar el tráfico de red en tiempo real.
Agricultura inteligente y sostenibilidad
Incluso el sector primario ha sido transformado por el uso de datos. La agricultura de precisión combina sensores, satélites y algoritmos para:
🔶 Optimizar riego y uso de fertilizantes según las condiciones del suelo.
🔶 Predecir cosechas y ajustar la cadena logística.
🔶 Disminuir el impacto ambiental al reducir el desperdicio de recursos.
🔶 Analizar condiciones climáticas en tiempo real para la toma de decisiones inmediatas.
Ejemplo: compañías como Syngenta y John Deere emplean plataformas de datos cloud y machine learning para mejorar el rendimiento agrícola por hectárea.
Otras industrias que dependen del Data Science:
🔷 Gobierno y sector público: para monitoreo de políticas públicas, análisis poblacional y predicción de riesgos.
🔷 Medios y entretenimiento: para recomendaciones personalizadas, y análisis de audiencias y clientes en plataformas como Netflix o Spotify.
🔷 Educación: para medir el rendimiento académico de estudiantes, personalizar procesos de aprendizaje y mejorar la retención estudiantil.
Cada industria necesita científicos de datos, ingenieros de Big Data y analistas especializados que sepan extraer conocimiento valioso de fuentes de datos masivas, y la capacidad de aplicar Big Data a diferentes sectores convierte a esta disciplina en una de las más versátiles y con mayor proyección profesional.
En el programa de TripleTen, aprenderás a resolver problemas reales de negocio con las herramientas líderes del sector, lo que te preparará para impactar directamente en el mundo empresarial con tus habilidades en datos.
¿Qué tendrás en tu portafolio al terminar el módulo de Big Data?
El curso de Big Data de TripleTen está diseñado para que salgas con proyectos listos para mostrar en entrevistas, además de que tu portafolio reflejará las habilidades más buscadas en la industria. Nada de ejercicios genéricos: trabajarás con datos reales y resolverás problemas empresariales con impacto.
Proyectos clave que construirás
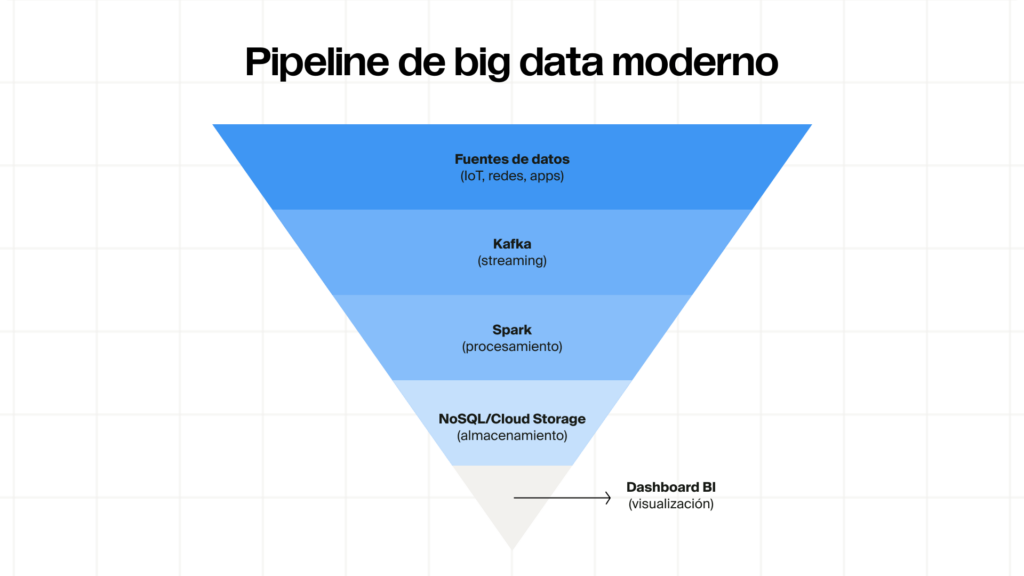
Pipeline completo de datos en la nube
Desde la ingesta de datos en streaming con Kafka hasta el almacenamiento en bases NoSQL (MongoDB, Cassandra) y visualización con herramientas de BI.
Análisis de grandes volúmenes de datos con Spark
Procesarás datasets masivos en Apache Spark; aplicarás transformaciones, agregaciones y modelos analíticos en memoria.
Dashboard interactivo para toma de decisiones
Diseñarás visualizaciones accionables con datos reales de sectores como finanzas, e-commerce o salud.
Simulación de arquitectura escalable para una empresa real
Diseñarás y documentarás una solución distribuida para un problema concreto; por ejemplo, detección de fraude, predicción de fallos o segmentación de clientes.
Cada uno de estos proyectos te permitirá demostrar:
🔶 Dominio de herramientas como Hadoop, Spark, Kafka y bases de datos NoSQL.
🔶 Capacidad para trabajar en entornos cloud con AWS, GCP o Azure.
🔶 Pensamiento crítico para resolver problemas complejos con datos reales.
🔶 Comunicación clara de resultados técnicos a equipos de negocio.
Recuerda que tu portafolio será tu mejor carta de presentación para postularte a roles como Big Data Engineer, Data Architect o Cloud Data Analyst.

¿Cuánto gana un especialista en Big Data en México?
La especialización en Big Data es una de las rutas profesionales con mayor crecimiento y mejor remuneración dentro del sector tecnológico. A medida que más empresas mexicanas y globales invierten en el análisis de datos a gran escala, la demanda de talento calificado en este campo aumenta, y con ella, los salarios.
Sueldos promedio por nivel de experiencia
Los ingresos pueden variar según tu nivel, pero incluso los perfiles junior comienzan con salarios competitivos:
🔷 Junior (0-3 años de experiencia): entre $18,000 y $25,000 MXN mensuales.
Estos perfiles suelen trabajar como asistentes de análisis, ingenieros de datos en entrenamiento o en soporte a equipos senior, dominando herramientas como SQL, Python y plataformas cloud.
🔷 Mid-level (3-6 años): entre $26,000 y $45,000 MXN mensuales.
Suelen liderar proyectos de integración de datos, crear pipelines complejos, optimizar el rendimiento de sistemas distribuidos y participar en decisiones estratégicas de arquitectura.
🔷 Senior (7-10+ años): desde $45,000 hasta $70,000+ MXN mensuales.
A este nivel, los roles incluyen arquitectos de datos, líderes técnicos o especialistas en infraestructura Big Data. Muchos tienen experiencia en Spark, Hadoop, Kafka y arquitecturas cloud a gran escala.
🔷 Especialistas y líderes en empresas globales: hasta $100,000 MXN o más mensuales.
Según datos de Glassdoor y Jobted de 2025, los salarios en Big Data superan en promedio un 30% a los de un analista de datos tradicional, sobre todo en empresas multinacionales, fintechs, healthtechs o consultoras de transformación digital.
Diferencias salariales por ciudad
La ubicación también influye en el rango salarial. A continuación, te mostramos un resumen de las tres principales ciudades con ecosistemas tecnológicos sólidos:
Ciudad de México (CDMX)
🔶 Rango medio: $38,000 - $55,000 MXN/mes.
🔶 Rango alto: Hasta $90,000 MXN/mes.
La Ciudad de México concentra la mayor cantidad de oportunidades en Big Data por la presencia de bancos, aseguradoras, consultoras globales y corporativos. También es común que empresas extranjeras contraten talento remoto con salarios competitivos.
Monterrey
🔶 Rango medio: $32,000 - $50,000 MXN/mes.
🔶 Sectores destacados: energía, manufactura, fintech.
Muchas empresas tecnológicas e industriales invierten en análisis predictivo, IoT industrial y automatización basada en datos. Los sueldos se complementan con bonos de productividad, prestaciones privadas y desarrollo profesional.
Guadalajara
🔶 Rango medio: $28,000 - $45,000 MXN/mes.
🔶 Potencial de crecimiento: Alto.
Guadalajara es considerada el "Silicon Valley mexicano" por su ecosistema de innovación, startups y centros de desarrollo de grandes firmas como Oracle, Intel y HP. Las oportunidades en ciencia de datos y Big Data crecen rápidamente, especialmente en proyectos de Machine Learning, IA y análisis en tiempo real.
¿Por qué los sueldos en Big Data son tan competitivos?
Los especialistas en Big Data ocupan una posición estratégica dentro del ecosistema tecnológico, por su capacidad para dar soporte, procesar y analizar grandes volúmenes de datos en tiempo real. Esto los convierte en piezas clave en la transformación digital de las organizaciones.
Estas son algunas de las razones por las que sus sueldos están por encima del promedio:
¿Por qué los sueldos en Big Data son tan competitivos?
Los especialistas en Big Data ocupan una posición estratégica dentro del ecosistema tecnológico, por su capacidad para dar soporte, procesar y analizar grandes volúmenes de datos en tiempo real. Esto los convierte en piezas clave en la transformación digital de las organizaciones.
Estas son algunas de las razones por las que sus sueldos están por encima del promedio:
✅ Alta demanda vs. escasa oferta de talento especializado
Aunque el interés por Big Data ha crecido, aún existe una brecha importante entre la demanda del mercado y la cantidad de profesionales con conocimientos técnicos avanzados en tecnologías como Spark, Hadoop o arquitecturas distribuidas. Esta escasez eleva el valor del talento calificado.
✅ Big Data es el motor de decisiones estratégicas
Sectores como banca, retail, salud, logística y tecnología confían en los datos para anticipar tendencias, reducir riesgos, personalizar experiencias y optimizar operaciones. Las empresas necesitan expertos que transformen datos en decisiones de negocio concretas.
✅ Certificaciones técnicas que elevan el perfil profesional
Las certificaciones en plataformas líderes como AWS, Google Cloud o Microsoft Azure no solo validan conocimientos, sino que abren puertas a roles mejor remunerados y a proyectos internacionales; dan soporte a todo lo que aprenderás a hacer.
✅ Acceso a empleos remotos con sueldos globales
Cada vez más empresas internacionales contratan talento en México para roles de Big Data y Data Science, con salarios en dólares y oportunidades de crecimiento profesional sin necesidad de reubicarse.
✅ Big Data es parte del top de salarios en tecnología
Según reportes de Glassdoor, Talent.com y LinkedIn Jobs, los roles relacionados con Data Science, Big Data Engineering y Cloud Analytics están entre los mejor pagados en la industria tech, con tendencias de crecimiento sostenido para los próximos años.
✅Proyectos de alto impacto y alta responsabilidad
Quienes trabajan en Big Data están a cargo de arquitecturas que procesan millones de datos por minuto, lo que implica responsabilidad crítica, soporte y dominio técnico avanzado. Esto se traduce en sueldos más altos que otros roles junior en tecnología.
Casos de éxito de estudiantes
En TripleTen, estudiantes han pasado de ser analistas de datos a Big Data Engineers en startups tecnológicas y corporaciones globales. Sus historias demuestran cómo la combinación de teoría, práctica y mentoría abre puertas a posiciones estratégicas. Estas son algunas de sus opiniones:
«El curso me dio un amplio conocimiento del tema y lo mejor fue que me permitió aprender directamente de expertos, adquiriendo conocimientos de primera mano.»
– Irene Reynoso, Graduada de Data Science
«Tuvo un gran impacto en mi vida, pues no solo me permitió estudiar 2 carreras al mismo tiempo, sino tener un trabajo en el área casi de inmediato.»
– Benjamin Rodriguez, Graduado de Data Science



¡Recupera el dinero de tu educación en tus dos primeros meses de trabajo!
Preguntas frecuentes sobre el curso de Big Data
¿Qué es Big Data y por qué es importante?
¿Necesito experiencia previa en programación?
¿Qué tecnologías de Big Data aprenderé?
¿Cómo se diferencia de análisis de datos tradicional?
¿Qué oportunidades laborales me abre?
¿Trabajaré con datos reales de gran escala?
¿Es necesario conocer inteligencia artificial para Big Data?
¿Qué tipo de empresas necesitan especialistas en Big Data?
¿El curso incluye certificaciones en plataformas cloud?
¿Cuánto tiempo toma dominar las tecnologías de Big Data?
¿Por qué ahora es el mejor momento para especializarte en Big Data?
El crecimiento explosivo de los datos no se detiene. Con una tasa de generación de información que crece un 25% anual, las empresas necesitan profesionales capaces de convertir el caos en conocimiento estratégico. Hoy, aprender Big Data no es solo una ventaja competitiva: es una necesidad para quienes quieren mantenerse relevantes en el mercado laboral.
A medida que la inteligencia artificial, el aprendizaje automático y la automatización se integran en procesos clave, el dominio de Big Data se convierte en un pilar para acceder a oportunidades de alto impacto. Especializarte ahora te posiciona para aprovechar esta ola de transformación desde sus inicios.