A distancia
Curso Ingeniero de Datos: Domina Big Data e Infraestructura Cloud
Horario flexible a tiempo parcial que se adapta a tu estilo de vida
Comienza tu carrera en tecnología en 9 meses o te devolvemos tu dinero.

TripleTen está incluido por Forbes en "5 bootcamps de codificación a tener en cuenta"
El nuevo informe de TripleTen revela las tendencias de contratación de los profesionales que se orientan hacia la tecnología

TripleTen es el mejor bootcamp de Ingeniería de Software para 2024




¿Qué es Ingeniería en Ciencia de Datos?
La ingeniería en ciencia de datos no es solo un concepto técnico. Es la base que hace posible transformar información cruda en soluciones listas para el análisis. Y para lograrlo, se necesitan sólidos conocimientos en matemáticas y una clara toma de decisiones estratégicas.
Piensa en todo lo que generamos a diario: publicaciones en redes sociales, datos de sensores IoT, movimientos en transacciones financieras, interacciones desde dispositivos móviles...
¡La cantidad de datos crece a un ritmo sin precedentes! Y ahí es donde entra en juego una infraestructura robusta, capaz de capturar, procesar y mantener esa información en las condiciones óptimas, para que realmente sea útil desde un punto de vista técnico.
El objetivo de esta disciplina es simple pero crítico: que la información esté limpia, segura, estructurada y disponible justo en el momento en que se necesita. Así, científicos de datos, analistas y otros perfiles dentro de las organizaciones pueden acceder a informes precisos, identificar patrones y desarrollar modelos predictivos que aporten ventajas competitivas reales.
¿Qué hace un ingeniero de datos?
Un ingeniero de datos:
🔷 Diseña, implementa y mantiene sistemas de extracción, transformación y carga.
🔷 Asegura seguridad y disponibilidad.
🔷 Habilita análisis y modelos.
🔷 Aporta soluciones de alto impacto para distintas áreas de la organización.
Definición y conceptos clave de Ingeniería en Ciencia de Datos
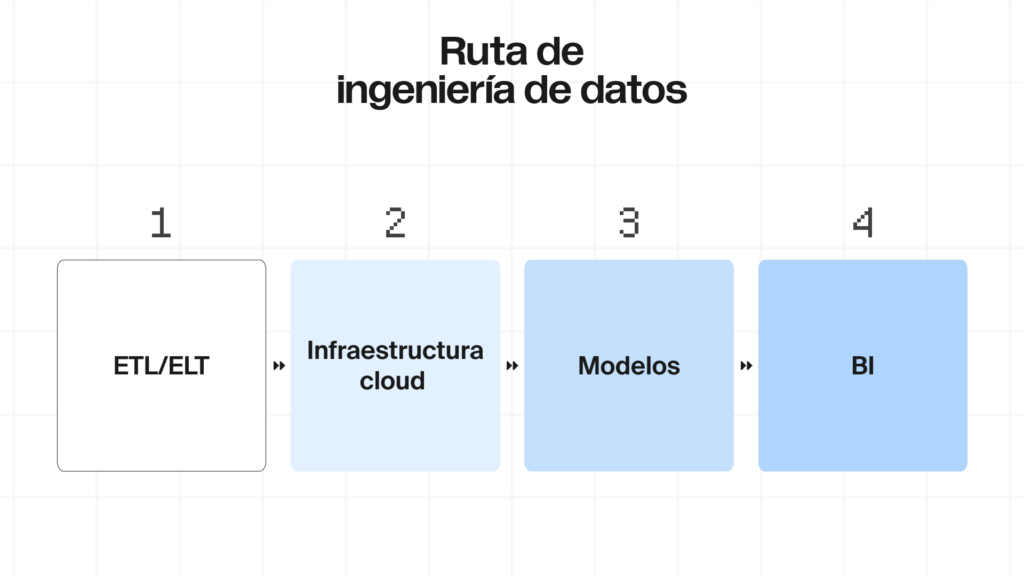
La ingeniería en ciencia de datos --también llamada ingeniería en datos-- va mucho más allá de un título técnico: es el arte y la ciencia de diseñar e implementar sistemas conocidos como pipelines. Estos pipelines son estructuras automatizadas que llevan a cabo procesos ETL (extracción, transformación y carga) o ELT (extracción, carga y transformación) para mover y preparar la información.
Imagina esto:
🔶 En el sector financiero, un pipeline puede procesar millones de transacciones, transformarlas para detectar posibles fraudes y cargarlas en un data warehouse listo para análisis en tiempo real.
🔶 En e-commerce, puede unir datos de inventario, patrones de compra y campañas de publicidad para ajustar y optimizar estrategias de marketing.
Estos sistemas no solo deben funcionar; tienen que ser escalables, seguros y eficientes para sostener todas las operaciones de manejo de datos.
Esto implica trabajar con infraestructura cloud, herramientas de orquestación como Apache Airflow, procesamiento en tiempo real con Spark Streaming, y aplicar políticas de control y gobernanza de datos que cumplan con los estándares más exigentes.
Un ingeniero en ciencia de datos domina tecnologías como SQL avanzado, Python para manipulación de datos, y sabe desplegar productos y servicios en la nube con AWS, Azure o Google Cloud. Así, garantiza que toda la cadena de datos respalde el análisis de negocio, los tableros de inteligencia y las aplicaciones de Machine Learning.
Diferencias entre ingeniería de datos, ciencia de datos y análisis de datos
Aunque suenen parecidas, la ingeniería de datos, la ciencia de datos y el análisis de datos cumplen funciones muy distintas dentro del ecosistema de la información.
| Ingeniería de Datos | Es la base técnica. Se encarga de crear y mantener la infraestructura y los sistemas que permiten que los datos fluyan y se almacenen de forma correcta. Los ingenieros de datos construyen pipelines, administran bases y sistemas de almacenamiento, y se aseguran de que la información tenga calidad, seguridad y disponibilidad en todo momento. Es un trabajo esencialmente técnico y de infraestructura, donde cada detalle cuenta. |
| Ciencia de Datos | Aquí los datos ya están listos gracias a la ingeniería, y los científicos de datos los usan para realizar análisis avanzados, construir modelos predictivos y aplicar algoritmos de Machine Learning. Su misión es interpretar la información para responder preguntas complejas, descubrir patrones y respaldar la toma de decisiones estratégicas. |
| Análisis de Datos | Es la fase más orientada a la comunicación de resultados. Los analistas de datos exploran, visualizan y reportan la información para explicar comportamientos y tendencias. Usan herramientas de BI como Power BI, ejecutan consultas SQL y preparan reportes claros para diferentes áreas del negocio. |
El curso de Ingeniería en Ciencia de Datos dentro del programa de Análisis de datos en TripleTen te prepara precisamente para ser ese eslabón técnico clave que hace posible todo lo demás. Aprenderás a construir infraestructuras sólidas que sostengan el trabajo de analistas y científicos de datos, y que garanticen el éxito de cualquier solución basada en datos.

Tecnologías y habilidades clave del Ingeniero en Ciencia de Datos
Un ingeniero en ciencia de datos, o Data Engineer, debe dominar:
🔷 SQL avanzado para consultas complejas y análisis.
🔷 Python para scripts de automatización, procesos ETL y manipulación de datos.
🔷 Plataformas en la nube (AWS, Azure, Google Cloud) para desplegar soluciones.
🔷 Herramientas de orquestación como Apache Airflow.
🔷 Procesamiento en tiempo real con Apache Kafka y Spark.
🔷 Principios de seguridad, protocolos de seguridad avanzada, control de acceso y optimización de costos en cloud.
¿Cuál es el rol del ingeniero en ciencia de datos en las grandes organizaciones?
En el entorno empresarial actual, donde el volumen de datos crece exponencialmente, el rol del ingeniero en ciencia de datos es estratégico y de alta demanda. Esto nos lleva a la pregunta: ¿cuánto gana un ingeniero de datos en la industria y las profesiones relacionadas?
Estos profesionales son responsables de crear sistemas robustos, capaces de procesar petabytes de datos provenientes de múltiples fuentes, dentro del ámbito de la ingeniería de datos: bases de datos, plataformas IoT, redes sociales, aplicaciones empresariales, sensores, entre otros.
El ingeniero de datos diseña arquitecturas escalables que permiten el procesamiento en tiempo real, lo que asegura que los datos de calidad estén disponibles para diversas áreas. Además, implementa políticas de seguridad y cumplimiento normativo para la protección de la información sensible.
El crecimiento de esta profesión no es casualidad, y está impulsado por la capacidad de responder a demanda de estudios en campos tecnológicos.
Según datos del 2024 de la Universidad Northeastern:
🔶 Hay un 35% de aumento anual en la demanda de roles de Data Engineer.
🔶 Salarios que superan los $120,000 USD promedio al año.
🔶 90% de las empresas Fortune 500 requieren estos perfiles para gestionar su infraestructura de datos.
Un ingeniero de datos diseña arquitecturas escalables para una compañía global, coordina la conexión entre múltiples fuentes y asegura que no haya problemas de calidad. Sus responsabilidades incluyen la optimización de costos en la nube y la transformación de información masiva en un formato listo para el análisis y otros servicios de datos.
Esto es lo que puedes ganar como Data Scientist o Data Engineer
Beneficios para empresas y profesionales
Para una empresa, contar con un profesional formado en ingeniería en ciencia de datos es como tener un motor de alto rendimiento para la toma de decisiones.
🔷 La investigación y el análisis se vuelven más precisos y confiables.
🔷 Los procesos son mucho más ágiles, y se implementan sistemas sólidos que reducen problemas de acceso y mantienen la información siempre lista.
🔷 Además, se logran soluciones de infraestructura optimizadas que mejoran el rendimiento y reducen costos.
Para ti como estudiante, este curso es una ruta directa hacia posiciones de alto valor en el mercado laboral. Te prepara para entrevistas técnicas y estratégicas en roles como Senior Data Analyst, Data Engineer o Business Intelligence Developer, entre otros.
También refuerza habilidades clave en matemáticas, tecnología y métodos que se aplican de manera real en la industria, lo que te prepara para aportar valor desde el primer día.
¿Quieres convertirte en un experto ingeniero de datos?
Accede al programa completo de analista de datos y aprende las competencias que empresas líderes valoran: extracción de información, optimización de sistemas, diseño de modelos y despliegue de soluciones cloud.
Inscríbete al programa de Analista de Datos y domina Data Engineering
Impacto inmediato en tu carrera
🔶 Demanda laboral: +35% de crecimiento anual en roles de Data Engineer.
🔶 $120,000 USD: sueldo promedio para ingeniero de datos en el mercado global.
🔶 90% de las empresas Fortune 500 requieren ingeniería de datos para su infraestructura analítica.
🔶 Hasta 40% de ahorro por optimización de sistemas y arquitectura en la nube.
🔶 Enfoque 100% práctico: proyectos con extracción, transformación, modelos y despliegue en cloud.
¿Para quién es este curso de ingeniero de datos?
🔷 Analistas que buscan pasar a ingeniería de datos y fortalecer su perfil con conocimientos en infraestructura.
🔷 Profesionales de TI que desean aplicación real en sistemas distribuidos, seguridad y optimización.
🔷 Personas con bases en SQL/Python que quieren trabajar como Data Engineer (incluye preparación para certificación y examen).
¿Qué beneficios obtendrás? (Orientados a resultados)
🔶 Diseñarás estructuras y pipelines para datos de gran tamaño con métodos robustos (ETL/ELT).
🔶 Integrarás conexión a fuentes múltiples (APIs, IoT, relacionales) con presentación de informes claros.
🔶 Aplicarás estrategias de seguridad, control y gobernanza exigidas por la industria.
🔶 Construirás productos y servicios de infraestructura que reducen problemas y elevan la capacidad analítica.
🔶 Ruta de carrera con roles como Ingeniero Analista de Datos, Data Engineer o BI Developer.
Conoce el temario y casos reales
Estas competencias te colocan en una posición estratégica dentro de cualquier empresa, ya que la ingeniería de datos es el eje que conecta las necesidades de negocio con las soluciones técnicas.
Con el dominio de herramientas avanzadas y software especializado, liderarás proyectos de Big Data que optimicen bases, automaticen procesos y mejoren la gestión de la información con un punto de vista técnico.
Proyectos reales: ¡portafolio listo para entrevistas!
🔷 Pipeline multifuente (APIs, IoT, relacional) con extracción y transformación hacia un modelo analítico.
🔷 Seguridad y control de acceso en datos sensibles (encriptación, roles).
🔷 Arquitectura cloud optimizada para millones de registros.
🔷 Optimización de sistemas legados: menos latencia, menos problemas, más capacidad.
Casos de uso reales de la ingeniería en ciencia de datos
La ingeniería en ciencia de datos es mucho más que un conjunto de conceptos: es el motor que impulsa soluciones que cambian el rumbo de las empresas.
Cada día, un ingeniero de datos se enfrenta a retos complejos que ponen a prueba su creatividad, su dominio técnico y su capacidad para transformar datos en resultados.
Imagina poder agregar a tus habilidades:
🔶 Optimizar un sistema de reportes en una compañía de retail que procesa millones de transacciones diarias para reducir tiempos y mejorar la toma de decisiones.
🔶 Implementar soluciones de infraestructura en la nube para una startup de logística, y dar visibilidad en tiempo real de cada vehículo y para entregar una experiencia impecable a los clientes.
🔶 Desarrollar modelos de datos que alimentan dashboards ejecutivos para una empresa de servicios financieros, permitiendo ver tendencias y oportunidades antes que la competencia.
🔶 Transformar y limpiar masivamente datos para un proceso de auditoría en una multinacional, y así asegurar seguridad (estándares internacionales de seguridad), control y cumplimiento.
Pero estos no son solo ejemplos: ¡son el tipo de proyectos que vivirás en el curso ingeniero de datos de TripleTen!
Con una formación 100% práctica, trabajarás con las mismas herramientas, métodos y tecnologías que usan las grandes organizaciones. Al finalizar, no solo dominarás la teoría, sino que tendrás en tus manos productos efectivos que habrás creado, listos para impresionar en entrevistas y abrirte las puertas de oportunidades reales.
Conoce más información sobre el curso
Si quieres conocer a detalle todos los temas, herramientas y proyectos que incluye este curso, no pierdas tiempo:
Este recurso gratuito te mostrará cómo está estructurado el contenido, qué tecnologías dominarás y cómo cada proceso de aprendizaje está pensado para llevarte de la teoría a la práctica de forma inmediata y con toda la preparación para tu examen de certificación.
Comparativa: TripleTen vs. Cursos generales
| Cursos generales | Este curso de Ingeniero de Datos (Domina Big Data e Infraestructura Cloud) |
| ⚪️ Es teoría suelta | 🟢 Es una aplicación con práctica enfocada a servicios reales |
| ⚪️ Formación limitada en herramientas | 🟢 Formación en herramientas actuales (Airflow, Kafka, Spark, cloud) y métodos de la industria |
| ⚪️ Sin preparación específica para roles de alto salario | 🟢 Preparación para certificación, examen y roles de alto sueldo |
| ⚪️ Sin acompañamiento personalizado | 🟢 Acompañamiento y asesoramiento en selección de proyectos y carrera |
| ⚪️ No alineado con la demanda laboral | 🟢 Alineado con profesiones y certificación |
| ⚪️ Ejercicio genéricos | 🟢 Casos reales con datos, pipelines y proyectos que aplican a entornos empresariales. |
Sprint 1 Python básico
2 semanas
Capítulo 1. Introducción a tu futura profesión
Capítulo 2. Variables, tipos de datos y operaciones aritméticas
Capítulo 3. Strings
Capítulo 4. Listas
Sprint 2 Python básico (continuación)
2 semanas
Capítulo 1. Bucles
Capítulo 2. Sentencias condicionales
Capítulo 3. Diccionarios
Capítulo 4. Funciones
Sprint 3 Manipulación de datos (Data Wrangling)
2 semanas
Capítulo 1. La librería Pandas
Capítulo 2. Leer y visualizar datos
Capítulo 3. Trabajar con valores duplicados y ausentes
Capítulo 4. Filtrado de datos
Sprint 4 Manipulación de datos (Data Wrangling) (continuación)
2 semanas
Capítulo 1. Tipos de datos
Capítulo 2. Ingeniería de características
Capítulo 3. Transformación de datos
Capítulo 4. Visualización de datos
Sprint 5 Análisis estadístico de datos
3 semanas
Capítulo 1. Estadística descriptiva
Capítulo 2. Teoría de la probabilidad
Capítulo 3. Prueba de hipótesis
Sprint 6 Proyecto del módulo 1
1 semana
Sprint 7 Herramientas de desarrollo de software
3 semanas
Capítulo 1. Introducción a la línea de comandos
Capítulo 2. Entornos de desarrollo
Capítulo 3. Git y GitHub
Capítulo 4. Python intermedio
Capítulo 5. Entorno de desarrollo individual
Sprint 8 Recopilación y almacenamiento de datos (SQL)
2 semanas
Capítulo 1. Recuperar datos de recursos en línea
Capítulo 2. SQL como herramienta para trabajar con datos
Capítulo 3. Funciones avanzadas de SQL para analistas
Capítulo 4. Relaciones entre tablas
Capítulo 5. Habilidades sociales (Soft skills)
Sprint 9 Introducción al machine learning
2 semanas
Capítulo 1. Entrenar tu primer modelo
Capítulo 2. Calidad del modelo
Capítulo 3. Mejora del modelo
Capítulo 4. Pasar a la regresión
Sprint 10 Aprendizaje supervisado
2 semanas
Capítulo 1. Codificación y estandarización de datos
Capítulo 2. Métricas de clasificación
Capítulo 3. Clasificación desbalanceada
Capítulo 4. Métricas de regresión
Capítulo 5. Habilidades sociales (Soft skills)
Sprint 11 Aprendizaje automático en negocios
2 semanas
Capítulo 1. Métricas de negocio
Capítulo 2. Implementar una nueva funcionalidad
Capítulo 3. Recopilación de datos
Capítulo 4. Habilidades sociales (Soft skills)
Sprint 12 Proyecto del módulo 2
1 semana
Sprint 13 Álgebra lineal
2 semanas
Capítulo 1. Vectores y operaciones vectoriales
Capítulo 2. Distancia entre vectores
Capítulo 3. Matrices y operaciones matriciales
Capítulo 4. Regresión lineal desde el interior
Sprint 14 Métodos numéricos
2 semanas
Capítulo 1. Análisis de algoritmos
Capítulo 2. Descenso de gradiente
Capítulo 3. Entrenamiento de descenso de gradiente
Capítulo 4. Potenciación del gradiente
Capítulo 5. Habilidades sociales (Soft skills)
Sprint 15 Series temporales
2 semanas
Capítulo 1. Análisis de series temporales
Capítulo 2. Pronóstico de series temporales
Sprint 16 Aprendizaje automático para textos
2 semanas
Capítulo 1. Vectorización de textos
Capítulo 2. Representaciones del lenguaje
Sprint 17 Visión artificial
2 semanas
Capítulo 1. Redes totalmente conectadas
Capítulo 2. Redes neuronales convolucionales
Capítulo 3. Habilidades sociales (Soft skills)
Sprint 18 Aprendizaje no supervisado
1 semana
Capítulo 1. Clustering
Capítulo 2. Detección de anomalías
Sprint 19 Proyecto final
2 semanas
Trayectoria profesional
Roles a los que podrás acceder:
🔷 Ingeniero de datos (Data Engineer).
🔷 Ingeniero de datos Jr.
🔷 Ingeniero analista de datos (Data Analyst Engineer).
Especializaciones técnicas:
🔶 Azure Data Engineer.
🔶 Cloud Data Engineer.
Sectores con mayor demanda:
🔷 Tecnología.
🔷 Finanzas.
🔷 Retail.
🔷 Logística.
🔷 Sociedad de la información.
Refuerza tu perfil
Con el programa completo de analista de datos (incluye presentación de informes, análisis y BI) podrás especializarte en ingeniería en ciencia de datos para manejar datos a escala.
🔶 Programa completo de Analista de Datos: aprende desde cero hasta un nivel avanzado en análisis de datos, visualización y BI. Ideal como base antes de especializarte en ingeniería en ciencia de datos. Incluye Power BI, SQL y estadística aplicada para negocios.
🔶 Especialización en Ciencia de Datos (Data Science): domina la creación de modelos predictivos, Machine Learning y análisis avanzado. Es la progresión natural después del curso de ingeniero de datos para aplicar ciencia a grandes volúmenes de datos.
🔶 Desarrollo Web Full-Stack: crea aplicaciones y servicios web capaces de consumir y mostrar información procesada por tus pipelines de ingeniería en datos. Aprende JavaScript, React, Node.js y bases de datos.
🔶 Curso UX/UI basado en Datos: diseña interfaces optimizadas usando métricas y analítica de usuarios. Perfecto para complementar tus habilidades técnicas con experiencia en la presentación de datos e interacción.
Algunos testimonios de nuestros alumnos




Aprende ingeniería en ciencia de datos desde cero y con acompañamiento
Si te identificas con alguna de las siguientes afirmaciones, aquí te tenemos una respuesta.
«No tengo suficiente experiencia en datos»
Este curso ingeniero de datos está diseñado para personas con conocimientos básicos de SQL y Python, y en matemáticas, pero con un interés real en aprender ingeniería en ciencia de datos aplicada. La formación incluye material introductorio, actividades guiadas y asesoramiento para que puedas seguir el proceso sin importar tu punto de partida.
«No sé si la inversión vale la pena»
Con un sueldo promedio global de $120,000 USD para un ingeniero de datos, más el crecimiento del +35% anual en la demanda laboral, la recuperación de tu inversión es rápida. La optimización de tu perfil profesional y las habilidades que obtendrás garantizan oportunidades en múltiples profesiones y sectores.
«No estoy seguro si podré aplicar lo aprendido»
Todos los proyectos son reales, extraídos de casos de organizaciones que trabajan con Big Data. Aprenderás extracción, transformación y carga de datos, infraestructura cloud, seguridad y control, y cómo diseñar modelos listos para el análisis en producción.
«Es muy técnico para mí»
La ruta de aprendizaje comienza con fundamentos claros y avanza hacia temas más especializados como Apache Airflow, Kafka, Spark, optimización de sistemas y servicios cloud, siempre con asesoramiento y práctica constante.
Beneficios adicionales de este Curso de Ingeniero de Datos
🔷 Aumentarás tu valor en la industria, con preparación para certificación y examen en AWS, Azure y Google Cloud.
🔷 Optimización de estructuras y métodos para trabajar con tamaño masivo de datos.
🔷 Aprendizaje de herramientas estándar que usan las empresas líderes.
🔷 Aplicación real de tecnología para resolver retos de organizaciones en diversos sectores.
🔷 Desarrollo de un perfil competitivo con capacidad de toma de decisiones basada en informes precisos.
¡Domina la Ingeniería en Ciencia de Datos y transforma tu carrera profesional!
En un mundo donde los datos y las matemáticas aplicadas mueven negocios, industrias y economías enteras, la ingeniería en ciencia de datos es el pilar que sostiene las decisiones más inteligentes.
Hoy las empresas que saben convertir datos en soluciones estratégicas lideran el mercado... ¡y tú puedes ser la mente que construya esa ventaja!
Completar el curso de ingeniero de datos de TripleTen no es solo una formación: es tu pase directo a una ruta profesional clara
Diseñado para que combines matemáticas, ciencia aplicada, tecnología avanzada y un enfoque 100% práctico desde el primer proyecto, este curso te preparará para cualquier examen de certificación.
Aprenderás a dominar la infraestructura cloud, la extracción de información, la optimización de sistemas, la transformación de procesos, y el despliegue de productos y servicios que tienen un impacto real en el mundo empresarial.
¿Por qué la ingeniería en ciencia de datos es la ruta en la economía actual?
Este curso de ingeniero de datos te brinda una base sólida para convertirte en un profesional altamente competitivo, listo para asumir el trabajo de ingeniero en datos en entornos de gran tamaño y alta demanda.
Podrás evolucionar hacia roles como ingeniero analista de datos, Data Engineer o incluso liderar proyectos como Azure Data Engineer.
Un curso diseñado para abrirte las puertas de las mejores oportunidades
Con TripleTen, tu ingeniería en ciencia de datos se convierte en una ingeniería en datos con visión de inteligencia organizacional, lo que te abrirá puertas en múltiples profesiones y asegurará que tu carrera esté respaldada por una ingeniería de ciencia de datos de primer nivel.
¡Es el momento de dar el paso y transformar tu futuro profesional! Domina la ingeniería en ciencia de datos y asegura tu lugar en uno de los campos más demandados y mejor pagados del mundo. Este curso ingeniero de datos será tu puerta de entrada a una carrera con alta demanda, excelentes sueldos y aplicación directa en proyectos reales de infraestructura y análisis de datos.
Preguntas frecuentes sobre el curso de ingeniero de datos
¿Qué es un ingeniero en datos?
¿Qué hace un ingeniero de datos?
¿Por qué necesito ingeniería de datos como analista?
¿Es muy técnico este curso?
¿Qué herramientas aprenderé?
¿Incluye preparación para certificación y examen?
¿Cómo se integra con el programa de Analista de Datos?
¿Qué oportunidades laborales ofrece?
¿Se trabaja con Big Data?
¿Necesito experiencia previa?