A distancia
Curso Python Para Ciencia de Datos

TripleTen está incluido por Forbes en "5 bootcamps de codificación a tener en cuenta"
El nuevo informe de TripleTen revela las tendencias de contratación de los profesionales que se orientan hacia la tecnología

TripleTen es el mejor bootcamp de Ingeniería de Software para 2024




Python para Ciencia de Datos que impulsa tu carrera
¿Te gustaría ser la mente detrás de la transformación de datos en decisiones estratégicas? Este módulo de Python para ciencia de datos es el punto de partida del programa completo de científico de datos de TripleTen. Aprenderás programación aplicada, análisis, visualización, y los fundamentos de Machine Learning con las herramientas y librerías que usa la industria.
🔷 Aprende el lenguaje de programación Python desde cero con enfoque 100% en datos. Este lenguaje de programación sigue siendo el más utilizado en el mundo según datos de Statista (2025).
🔷 Trabaja con pandas, NumPy, Matplotlib y Scikit-learn en proyectos reales.
🔷 Construye modelos que resuelvan un problema de negocio: desde limpieza y manipulación de conjuntos, hasta evaluación y despliegue.
🔷 Prepárate para roles en ciencia de datos, IA y Machine Learning.
Python no es solo otro lenguaje de programación: es la llave que abre la puerta a la ciencia de datos moderna. El 80% de los profesionales en este campo lo usan como su herramienta principal, desde los analistas en Amazon que predicen patrones de compra hasta los ingenieros de Spotify que personalizan playlists con machine learning. Con nuestro módulo de Python para Ciencia de Datos, no solo aprendes teoría: trabajas desde el inicio con proyectos reales y librerías que usan las grandes organizaciones.

Curso de Python para Ciencia de Datos
¿Qué lo hace diferente?
Este curso es una introducción intensiva y práctica a Python para el análisis y la creación de modelos en ciencia de datos (incluyendo análisis de datos con Python). Todo el material está diseñado para que aprendas conceptos clave y los apliques de inmediato; desde importar información desde archivos y web (APIs), hasta preparar conjuntos de datos, elaborar funciones reutilizables y entrenar algoritmos de Machine Learning con criterios de evaluación claros.
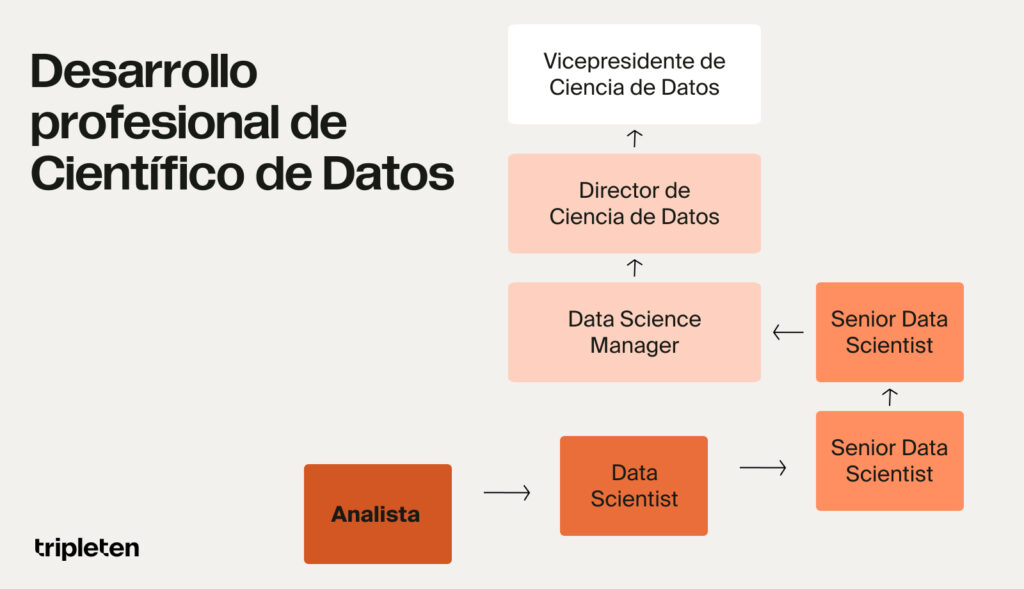
Esto es lo que ganan los científicos de datos
El rol para el que te estarás formando
Este módulo es tu puerta de entrada al programa completo de Ciencia de Datos de TripleTen, y su objetivo es prepararte para uno de los perfiles más demandados en tecnología: el Data Scientist.
Un científico de datos combina conocimiento técnico, visión analítica y habilidades de comunicación para:
🔶 Diseñar procesos de recolección y manejo de datos (ETL): construir flujos que extraen datos de múltiples fuentes, los limpian y los transforman en información lista para analizar.
🔶 Aplicar métodos estadísticos y algoritmos de Machine Learning: usar modelos predictivos para responder preguntas clave como: ¿Qué pasará si…?, ¿Cuál es la mejor decisión en este escenario?
🔶 Comunicar hallazgos: presentar insights a equipos técnicos y directivos con visualizaciones claras, dashboards y reportes interactivos.
🔶 Automatizar y escalar: implementar procesos que reduzcan el trabajo manual y optimicen el tiempo, midiendo el impacto en tiempo real.
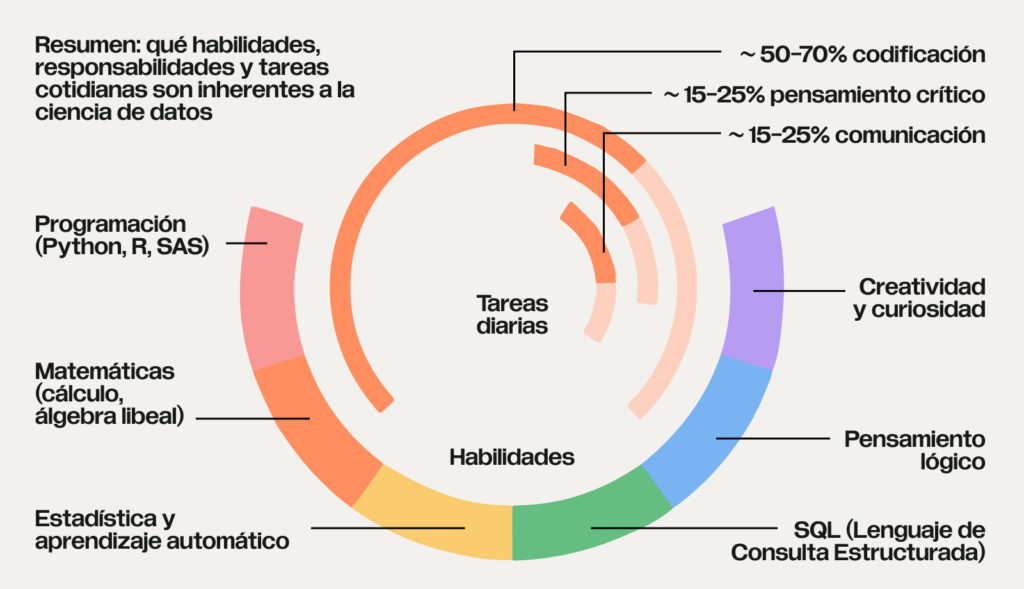
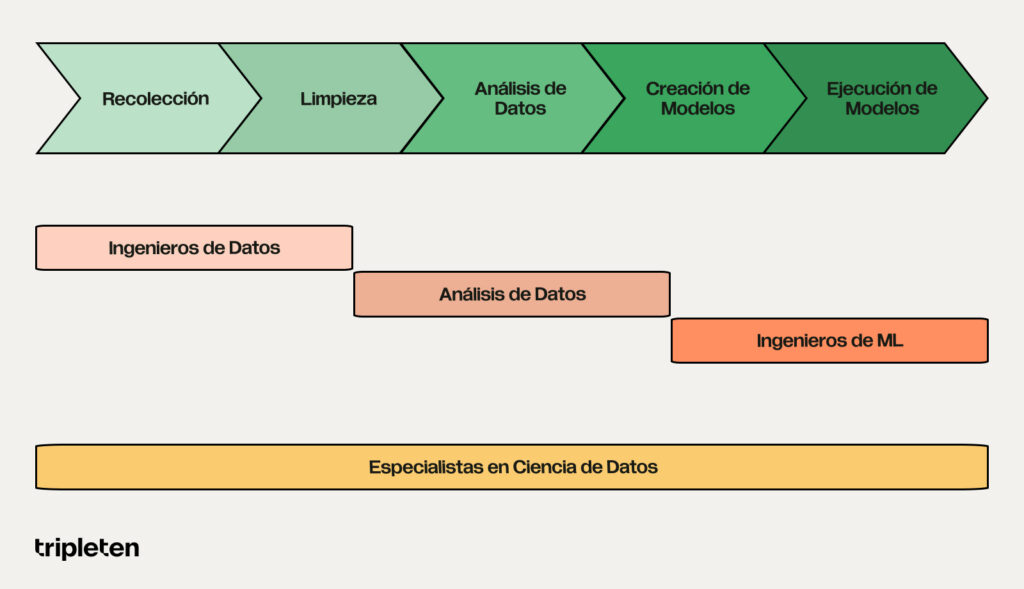
Preparación en Python: la clave del éxito
Python es el lenguaje más popular en ciencia de datos por su simplicidad y potencia. Sin embargo, no basta con conocer la sintaxis: necesitas aprender a usarlo estratégicamente para resolver problemas reales.
En este módulo, no solo aprenderás "qué botones presionar", sino cómo pensar como un analista y programador de datos.
Por qué esta preparación es esencial
Antes de avanzar a estadística avanzada, deep learning o MLOps, necesitas una base sólida en Python. Este módulo asegura que cada concepto que aprendas sea práctico y transferible:
🔶 Conexión con la realidad: no aprenderás funciones abstractas, sino cómo estas herramientas se usan en empresas de retail, salud, marketing y tecnología.
🔶 Práctica desde el inicio: cada tema incluye un mini-proyecto donde aplicarás el conocimiento inmediatamente.
🔶 Preparación para el siguiente nivel: cuando llegues a módulos más complejos, no perderás tiempo resolviendo dudas básicas.
🔶 Portafolio profesional: los proyectos que completes se convierten en evidencia tangible de tus habilidades ante los empleadores.
¿Cuáles son los beneficios de dominar el Análisis y Machine Learning?
🔷 Base sólida de Data Science con Python: desde tipos de datos y funciones, hasta clases, métodos y paquetes.
🔷 Dominio de pandas para manipulación y análisis de datos tabulares.
🔷 Visualización efectiva con Matplotlib (y una introducción a Seaborn) para explicar modelos y resultados.
🔷 Primeros modelos de Machine Learning con Scikit-learn: clasificación y regresión con evaluación correcta.
🔷 Proyectos guiados que simulan problemas reales de organizaciones.
Herramientas de Python que dominarás en este módulo
🔶 Pandas: Ideal para manipulación de datos. Ejemplo: importar un dataset de ventas y calcular el promedio de compra por cliente.
🔶 NumPy: Computación numérica de alto rendimiento. Ejemplo: operaciones con grandes volúmenes de datos en segundos.
🔶 Matplotlib y Seaborn: Visualización avanzada. Ejemplo: detectar tendencias en la caída de clientes con un gráfico de barras.
🔶 Scikit-learn: Machine learning aplicado. Ejemplo: crear un modelo de clasificación para predecir si un usuario hará una compra en línea.
¿Cuáles son los beneficios de estudiar en TripleTen?
🔷 Programa integral: este módulo es la puerta de entrada al programa completo de científico de datos, que incluye estadística, ML avanzado y MLOps.
🔷 Aprendizaje apegado a la industria: briefs, datos reales, revisión por mentores y pares.
🔷 Portafolio con proyectos verificables y modelos reproducibles.
🔷 Comunidad de estudiantes y egresados que comparten artículos, recursos y oportunidades.
🔷 Enfoque en seguridad de datos y buenas prácticas.
¡Con TripleTen aplicarás Python para la ciencia de datos del aula al mercado!

¿En qué industrias se necesita este rol?
La ciencia de datos con Python es una habilidad necesaria en todos los sectores que necesitan recopilar datos y medir resultados.
🔷 Finanzas y Risk scoring.
🔷 Retail y recomendadores (ej.: amazon-like).
🔷 Salud y análisis de información clínica.
🔷 Marketing con atribución y segmentación de usuarios.
🔷 Manufactura con control de calidad en tiempo real.
🔷 Web y producto digital (funnel, cohortes, growth).
🔷 Logística y optimización de procesos.
Imagina aplicar Python para ciencia de datos en proyectos reales...
🔶 Construirás un pipeline que limpia datos, crea features y entrena modelos en Python.
🔶 Darás soporte a un dashboard de visualización que guía decisiones diarias de un equipo de ventas.
🔶 Propondrás un experimento A/B y usarás funciones de evaluación para justificar tu recomendación.
🔶 Desarrollarás un código claro y replicable para otros usuarios del equipo.
Python para Ciencia de Datos
Según el Bureau of Labor Statistics (BLS) de EE. UU., el empleo en Python para ciencia de datos crecerá un 36% entre 2023 y 2033, un ritmo mucho mayor que el promedio de otras profesiones. Esta tendencia confirma que las habilidades en Python, análisis y Machine Learning son cada vez más valoradas.
Mercado con altos salarios
En cuanto a la compensación económica, el salario medio de un Data Scientist es de aproximadamente $122,700 USD al año, superando notablemente los ingresos de un analista de datos tradicional.

¿Este módulo es para ti?
Este módulo es para ti si:
 | Quieres transitar de análisis descriptivo a modelos predictivos con IA. |
 | Buscas una introducción práctica a Python para trabajar análisis de datos y Data Science con Python. |
 | Trabajas con información y necesitas estandarizar procesos de manejo de datos. |
 | Deseas una base sólida para continuar el programa completo y llegar a Machine Learning avanzado. |
¿Qué aprenderás en este curso?
| Core Python para Data Science | 🔷 Fundamentos de Python con enfoque en aplicaciones de ciencia de datos: tipos de datos, estructuras, funciones y clases. 🔷 Pandas para manipulación, filtrado, combinación y análisis de datasets de cualquier tamaño. 🔷 NumPy para cómputo numérico y operaciones con arrays de alto rendimiento. 🔷 Matplotlib y Seaborn para visualización avanzada y comunicación efectiva de resultados. 🔷 Introducción a Scikit-learn y sus algoritmos más utilizados en machine learning. |
| Data Analysis y Manipulación Avanzada | 🔶 Técnicas de limpieza y preprocesamiento de datos con Python. 🔶 Exploratory Data Analysis (EDA): cómo explorar y detectar patrones. 🔶 Análisis estadístico con librerías científicas de Python como SciPy y statsmodels. 🔶 Importación y exportación de datos desde múltiples fuentes: CSV, JSON, APIs, bases de datos SQL y NoSQL. 🔶 Transformaciones avanzadas y feature engineering para optimizar modelos predictivos. |
| Machine Learning Foundations | 🔷 Implementación de algoritmos de aprendizaje supervisado (regresión, clasificación) y no supervisado (clustering, reducción de dimensionalidad). 🔷 Validación de modelos con técnicas como cross-validation y train/test split. 🔷 Métricas de evaluación para medir y optimizar el rendimiento de modelos. 🔷 Introducción a deep learning: conceptos esenciales y librerías clave para dar el siguiente paso en IA. 🔷 Desarrollo y despliegue ligero de un proyecto de machine learning basado en datos reales. |
¿Por qué este curso es diferente?
¡Olvídate de formaciones genéricas que solo rozan la superficie! Aquí aprenderás sobre:
 | Data Science con Python enfocado en negocio: no es desarrollo web generalista. |
 | Librerías científicas y metodología de análisis; no solo ejercicios sueltos. |
 | Proyectos reales y evaluación rigurosa; no teoría sin aplicación. |
 | Preparación para cursos de Data Scientist y certificaciones. |
Para avanzar de forma estratégica, puedes seguir esta ruta de formación en TripleTen:
🔶 TripleTen Data Analysis Program → El punto de partida ideal para construir bases sólidas en análisis de datos, SQL, estadística y visualización.
🔶 TripleTen Data Science Program → El siguiente paso para dominar Machine Learning, modelado avanzado y habilidades de ciencia de datos a nivel profesional.
🔶 TripleTen Web Development Program → Aprende a llevar tus conocimientos de Python al desarrollo de aplicaciones web y APIs de predicción que usen datos en tiempo real.
🔶 TripleTen UX/UI Course → Diseña interfaces efectivas y experiencias interactivas centradas en el usuario para la visualización y consumo de datos.
Con esta formación, no solo dominarás herramientas técnicas clave, sino que tendrás la preparación para conectar negocio y tecnología, liderar proyectos de datos y acceder a oportunidades en sectores como tecnología, finanzas, salud, retail o investigación.
Testimonios quienes han estado ahí




Si aún tienes dudas como estas...
Empezarás con fundamentos e introducción progresiva. El material incluye ejemplos, plantillas y revisión.
«¿Y si me interesa R?»
Verás comparativas breves entre R y Python; aunque nosotros apostamos por Python, por su adopción y ecosistema.
«No sé si tendrá impacto en mi trabajo.»
Cada tema que se trata en el curso se liga a un problema real, con métodos de evaluación y entregables aplicables a casos reales.
«¿Qué hay del precio?»
Consulta planes y esquemas de precio flexibles. Recuerda que esta base servirá para acelerar tu retorno con decisiones de mayor impacto.
Un último impulso: piensa en tu «yo» de 6 meses adelante
Imagina abrir tu computadora y ver un portafolio que no solo demuestra lo que sabes, sino lo que eres capaz de crear:
🔶 Dashboards que guían decisiones clave en tiempo real.
🔶 Modelos de Machine Learning que predicen comportamientos y tendencias.
🔶 Código claro y eficiente que otros pueden usar y mejorar.
En solo seis meses, habrás pasado de conocer los conceptos básicos a resolver problemas reales con datos. Todo empieza aquí, con Python. Este lenguaje es la llave que abre la puerta a la ciencia de datos, al aprendizaje automático y a una carrera en tecnología con impacto tangible.
No se trata solo de estudiar, sino de demostrar tu valor con evidencia que cualquier empresa puede reconocer. Empieza hoy y construye la base sólida que te llevará a tu próximo gran paso profesional.
Tu CV después de TripleTen

Data Scientist


GitHub
Educación
Ene-Sept 2025
Sueldo esperado
Habilidades duras

Python

Pandas

Numpy

Matplotlib

Scikit-learn

Git

GitHub

SQL

Seaborn

Plotly

Keras

JSON
Soft Skills
Pensamiento analítico
Resolución de problemas
Comunicación de datos
Trabajo en equipo
Adaptabilidad
Aprendizaje continuo
Proyectos
+500 horas en Python, Machine Learning, análisis estadístico y visualización de datos
Preguntas frecuentes sobre Python para Ciencia de Datos
¿Por qué Python es el mejor lenguaje para ciencia de datos?
¿Qué librerías de Python aprenderé?
¿Necesito experiencia previa en programación?
¿Cómo se diferencia de otros cursos de Python?
¿Qué tipo de proyectos realizaré?
¿Este módulo me prepara para ser data scientist?
¿Aprenderé también R o solo Python?
¿Qué oportunidades laborales se abren?
¿Cuánto tiempo toma dominar Python para Data Science?
¿Incluye certificaciones?
