Una guía completa para la ciencia de datos
En las grandes empresas, un proyecto de ciencia de datos suele ser implementado por un gran equipo de diferentes especialistas en TI. Los ingenieros de datos, los analistas de datos y los científicos de datos participan en diferentes etapas del trabajo. Los ingenieros y científicos de datos participan en la recopilación de datos y el aprendizaje automático. Veamos en qué consiste el trabajo de los científicos de datos.
Primero, ¿qué es la ciencia de datos?
Hay muchos datos en el mundo y estos solo aumentan con el tiempo. Ya sean numéricos, de texto, en forma de imágenes o video, los usuarios generan datos todo el tiempo.
La ciencia de datos, o “data science” por su nombre en inglés, es una de las principales áreas de TI hoy en día. Los científicos de datos buscan formas de extraer información de grandes volúmenes de datos que ayuden a las empresas a tomar decisiones y hacer crecer su negocio. Por ejemplo, un científico de datos es capaz de predecir la demanda estacional de bienes o la probabilidad de pérdida de clientes con una metodología, y la ayuda de bases de datos y la inteligencia artificial.
En el curso de Data Science de TripleTen los estudiantes aprenden a crear programas basados en modelos matemáticos para buscar patrones en datos y realizar predicciones a través de sistemas informáticos.
Terminología básica que necesitas saber sobre la ciencia de datos
Para alguien que apenas inicia en el análisis de datos puede resultar difícil navegar por los conceptos, términos y tendencias de la ciencia de datos. La ciencia de datos se estructura de la siguiente manera:
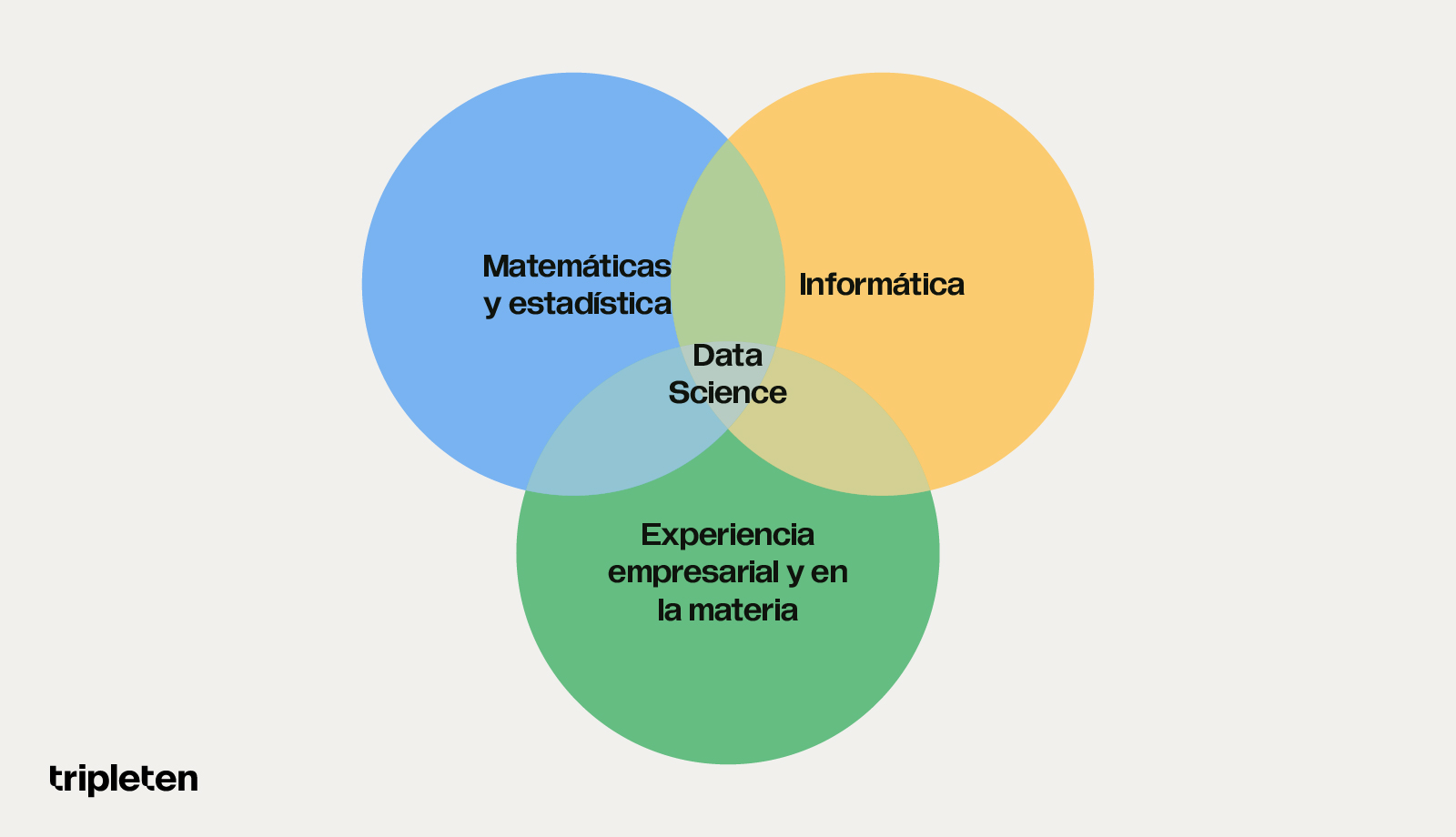
Redes neuronales
Una de las herramientas más innovadoras en Data Science son las redes neuronales. Una red neuronal es una base de datos compleja en la que las celdas están interconectadas mediante fórmulas. Los datos ingresan por un extremo de la base de datos, se procesan mediante una variedad de fórmulas, y se generan por el otro extremo. Configurar estas fórmulas es tarea de un especialista en Machine Learning o un científico de datos.
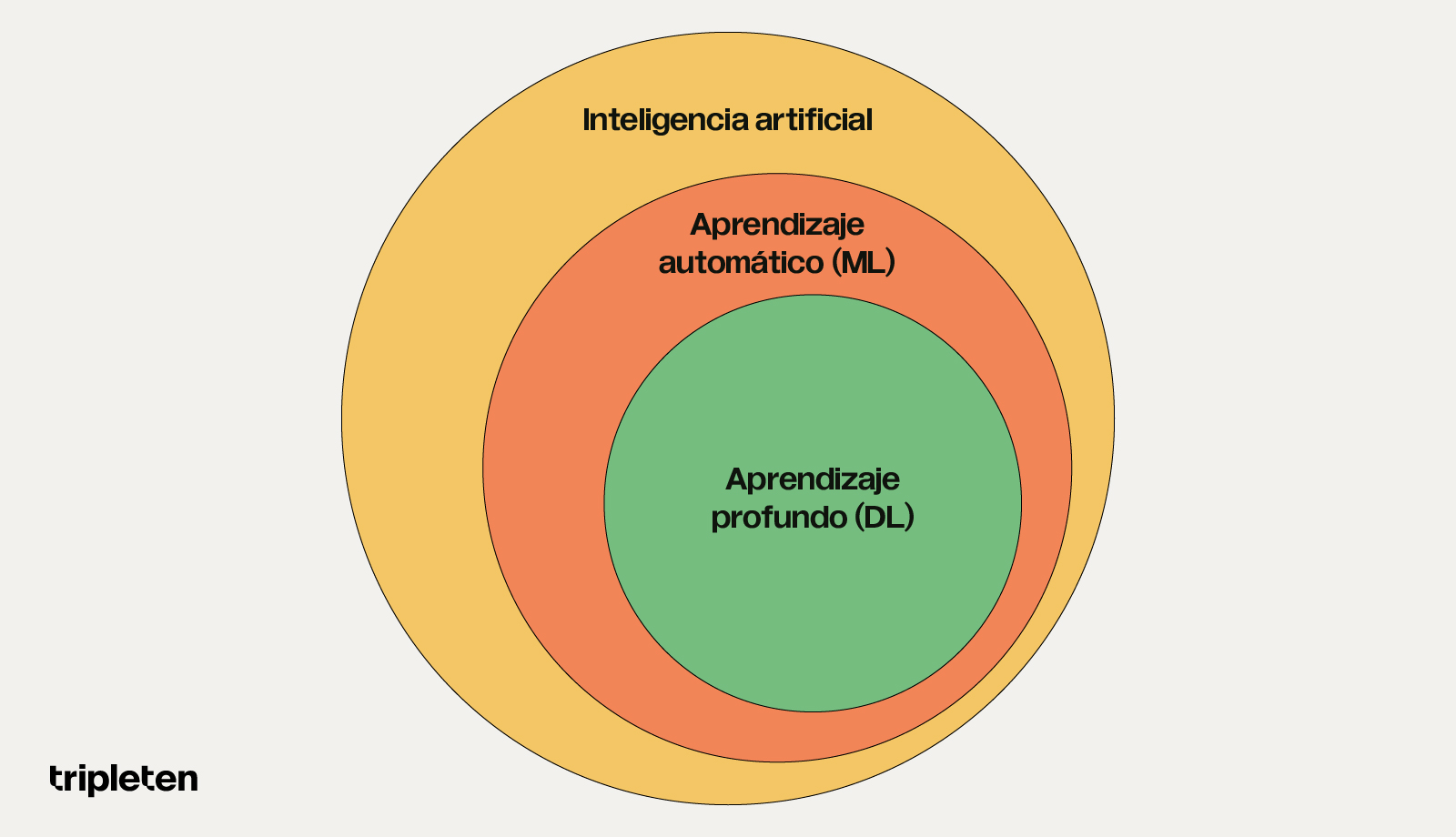
Inteligencia artificial (IA)
La inteligencia artificial (IA) es la creación y desarrollo de sistemas capaces de resolver problemas intelectuales. Son sistemas que, por ejemplo, son capaces de reconocer síntomas de enfermedades en imágenes médicas o jugar al ajedrez con una persona. Las tecnologías de inteligencia artificial trabajan con big data, utilizando diversos métodos para crear algoritmos que imitan el pensamiento humano. Cualquier modelo de inteligencia artificial es una red neuronal, algo así como un modelo de cerebro ideal.
Aprendizaje automático, o Machine Learning (ML)
El aprendizaje automático, o “machine learning (ML)” por su nombre en inglés, es una rama de la inteligencia artificial que se centra en entrenar sistemas informáticos para que puedan resolver problemas y hacer predicciones basadas en datos. Por ejemplo, un sistema de aprendizaje automático podría predecir el tiempo durante un mes basándose en las observaciones meteorológicas de los 10 años anteriores. Los algoritmos de recomendación en plataformas de música como Spotify o YouTube se basan en tecnologías de Machine Learning.
El Machine Learning utiliza modelos—programas que se basan en algoritmos, como árboles de decisión y regresión lineal—para cargar big data, analizar la información y trabajar con ella de acuerdo al algoritmo determinado. Si planeas elegir el aprendizaje automático entre todas las áreas de la ciencia de datos, Python es el lenguaje principal que deberás aprender para la programación de redes neuronales y análisis de datos.
Aprendizaje profundo, o Deep Learning (DL)
El aprendizaje profundo, o “deep learning”, es un tipo más complejo de aprendizaje automático. Se basa también en redes neuronales para resolver problemas más complejos. Sin embargo, por esa razón el Deep Learning requiere incluso más datos que el Machine Leaning. Algunos ejemplos de sistemas que utilizan aprendizaje profundo son ChatGPT, YaGPT y Midjourney, pues son sistemas de computación entrenados para reconocer voces y objetos en imágenes, analizar texto, y generar respuestas a las solicitudes de los usuarios, entre otras cosas.
Habilidades necesarias para la ciencia de datos
Los especialistas en ciencia de datos trabajan con Big Data, que son terabytes de información de diferentes fuentes. El Big Data son cantidades tan grandes de información, que es imposible recopilarla y procesarla de forma manual. De manera que los científicos de datos buscan formas de analizar y extraer la información necesaria para crear sus propias bases de datos.
Tomando esto en cuenta, lo que necesitas para trabajar en ciencia de datos es:
Conocer de programación
Los científicos de datos necesitan conocimientos y habilidades informáticas. Actualmente, las principales son la programación en Python y SQL, y el procesamiento de Big Data. Pero las herramientas están en constante evolución; por tanto, es importante estar preparado para aprender nuevos programas y lenguajes de programación.
Comprender las matemáticas y la estadística
Los algoritmos matemáticos son la base de la ciencia de datos. Para trabajar en Data Science, necesitas tener una base de conocimientos y metodologías, como el álgebra lineal, el análisis matemático, la teoría de la probabilidad y estadística, entre otros. Sin estos conocimientos, te será difícil comprender los algoritmos de los modelos de aprendizaje automático y seleccionar los adecuados para las tareas comerciales.
Comprender el dominio y funcionamiento del negocio
Para encontrar soluciones eficaces a los problemas, es necesario estudiar el área para la que se necesitan estas soluciones. A menudo, un científico de datos no trabaja para los clientes de forma permanente, sino que se le invita a implementar un proyecto específico—por ejemplo, encontrar formas de reducir costos o mejorar la logística. Y lo más importante: un científico de datos comienza cada nuevo proyecto investigando las propiedades de la empresa y su mercado.
Ser un pensador analítico
Para muchos profesionales, el pensamiento analítico es una habilidad “blanda”. Sin embargo, para los científicos de datos el pensamiento analítico es una competencia profesional obligatoria. Mientras trabaja, debe hacer preguntas, buscar patrones y predecir posibles resultados. Por tanto, el pensamiento analítico a menudo figura como un requisito para las posiciones de Data Science.
Ser capaz de visualizar datos
Esto quiere decir que la persona debe ser capaz de presentar datos en forma gráfica; por ejemplo, en forma de cuadros, histogramas, mapas, paneles, etc. La visualización simplifica el trabajo con datos, pues permite ver claramente la metodología, los resultados del análisis, identificar rápidamente patrones y plantear hipótesis con mayor facilidad. Los analistas y especialistas en Data Science utilizan herramientas como Matplotlib, Seaborn, Plotly, entre otras, para visualizar datos.
Además, para incursionar en la ciencia de datos se necesita un profundo conocimiento en Python, y aprender a trabajar con redes neuronales. Esto significa mucha programación en Python, bibliotecas, marcos, API, bases de datos, pruebas y computación en la nube. Todo esto permite a los desarrolladores crear redes neuronales, dedicarse a la visión por computación, la inteligencia artificial, los asistentes de voz y, en general, estar por delante de la informática.
¿Dónde se aplica la ciencia de datos?
Los especialistas en ciencia de datos trabajan en diferentes campos. Éstos son algunos de ellos:
- Data Science para medicina
La ciencia de datos trabaja sistemas que ayudan a los médicos a diagnosticar a los pacientes con ayuda de la computación y el Machine Learning, en función de los resultados de sus pruebas. Los modelos de estos sistemas se entrenan basándose en una gran cantidad de datos médicos: rayos X, datos de laboratorio, resonancia magnética, tomografía computarizada, entre muchos otros. Las tecnologías automatizan el trabajo rutinario de los médicos, de modo que no necesitan perder horas en estudiar imágenes, porque los sistemas les indican a qué prestar atención. Esto acelera el diagnóstico y el tratamiento.
- Técnicas de ciencia de datos empresariales
La ciencia de datos ayuda a las empresas a resolver tareas como elaborar previsiones financieras, gestionar riesgos, evaluar posibles inversiones, analizar el mercado y la competencia, analizar el comportamiento de los usuarios e, incluso, algo tan rutinario como encontrar las mejores rutas para el transporte de mercancías.
- Científicos de datos industriales
Los cientificos de datos industriales ayudan a controlar la calidad del producto, monitorear la condición técnica de los equipos, identificar rápidamente anomalías en su operación y optimizar los procesos de producción.
- Seguridad de la información
Para reconocer ataques cibernéticos y monitorear el acceso no autorizado a los datos, se utilizan algoritmos de Machine Learning y Big Data. Los modelos entrenados con big data son capaces de detectar diversas desviaciones; por ejemplo, el comportamiento inusual de un usuario en línea, que puede deberse a un pirateo de cuentas. Estos modelos ayudan a los profesionales de la seguridad de la información a tomar conciencia rápidamente de problemas potenciales.
Los métodos de la ciencia de datos también se utilizan para encontrar errores en los sistemas que los hacen vulnerables a la piratería.
Principales etapas del trabajo con datos
Comúnmente, el trabajo en un proyecto de ciencia de datos se divide en cuatro grandes etapas:
Crear requisitos de datos
Primero, se determina el objetivo del proyecto. Por ejemplo, una empresa necesita pronosticar la demanda de bienes, es decir, cuándo y qué se compra con mayor frecuencia. Para comprender qué datos ayudarán a lograr el objetivo, es importante estudiar su área (el mercado, los competidores, etc.), para después recopilar los requisitos de datos en especificaciones técnicas.
Preparar los datos
Digamos que a un científico de datos le proporcionan datos de los pedidos de los últimos diez años. Lo siguiente que debe hacer es asegurarse de que los datos sean adecuados para entrar en el modelo.
Los datos se limpian de errores como valores duplicados, omisiones, errores tipográficos y anomalías. También se realizan análisis de datos exploratorios (o EDA por sus siglas en inglés) para encontrar patrones, desviaciones, conexiones y dependencias entre variables. Para ello, se utilizan métodos como el análisis factorial, de correlación y de clusters.
Encontrar una solución
Según el problema se elige el enfoque para resolverlo. Esta etapa es para conocer sobre qué datos se harán los diferentes modelos de aprendizaje automático, y cómo funcionan estos modelos, para saber qué resultados darán.
Por ejemplo, la regresión lineal predecirá la demanda de un proyecto, pero solo si existe una relación lineal entre los factores que influyen en esta demanda. Si este no es el caso, es mejor utilizar otros modelos, pero claro, este es solo un ejemplo. Puedes seleccionar varios modelos a la vez para probarlos y comparar los resultados.
Construir un modelo
En esta última etapa se construyen y entrenan los modelos. Luego se verifica la exactitud del trabajo con una pequeña cantidad de datos reales. Si el modelo no funciona, se ajustan los parámetros de la muestra de entrenamiento o se selecciona un nuevo modelo para formar una muestra de datos diferente.
A pesar de que trabajar en ciencia de datos supone algunas dificultades al principio, es un campo de conocimiento sumamente amplio, que se mantiene en constante crecimiento. Una vez que domines esta ciencia, podrás conseguir trabajos de gran demanda e influir en la resolucion de problemas de las empresas. Conviértete en un científico de datos completo en tan solo nueve meses con el curso de científico de datos de TripleTen.
