Análisis exploratorio de datos: qué es y por qué es importante
El análisis exploratorio de datos (EDA) se describe como “una filosofía” sobre cómo se deben analizar los datos. Es decir, funciona como un estudio preliminar de un conjunto de datos con el fin de determinar sus principales características y relaciones entre características para crear un modelo de aprendizaje automático (ML).
El EDA implica el uso de varias técnicas—muchas de las cuales incluyen métodos de visualización de datos—para obtener información sobre los datos y validar los supuestos en los que basaremos nuestras inferencias. Veamos en qué etapas se divide el análisis exploratorio de datos y algunas de los métodos más comunes para hacerlo.

Importancia del análisis exploratorio de datos
El análisis exploratorio de datos es, de hecho, un enfoque del análisis de datos. Sin embargo, difiere del enfoque clásico en la forma misma en que busca abordar y encontrar una solución a un problema. El análisis de datos clásico tiene como objetivo generar predicciones a partir de modelos y generalmente es de naturaleza cuantitativa; EDA, por otro lado, es un enfoque centrado en datos, tanto en su estructura como en los modelos que sugiere. Con el análisis exploratorio de datos, el conjunto de datos recopilados se analiza primero para inferir qué modelo sería mejor para los datos, de acuerdo con su estructura subyacente.
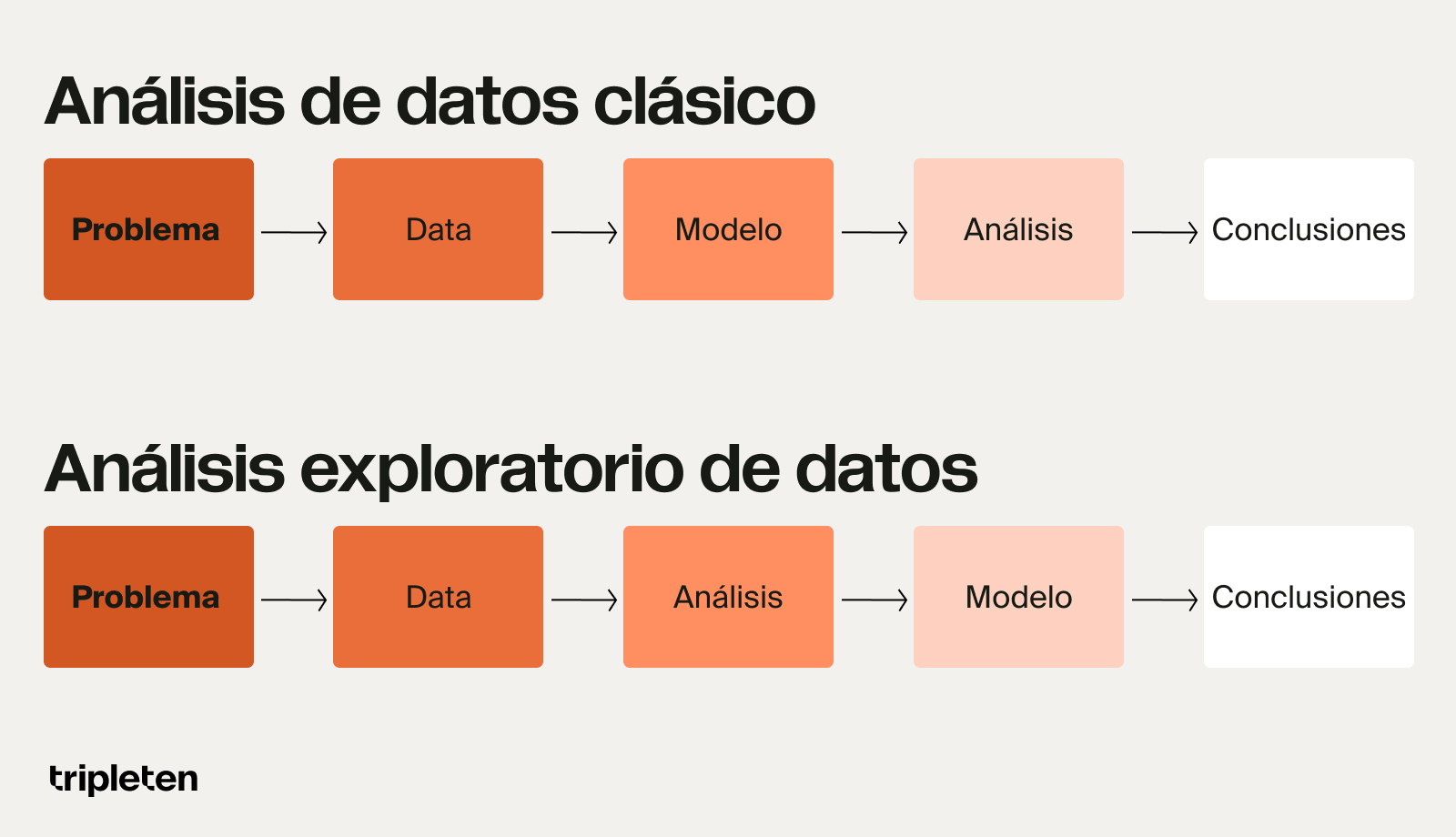
Los dos métodos difieren incluso en la forma en que manejan la información. Las técnicas de estimación clásicas se centran sólo en unas pocas características importantes, mientras que las técnicas EDA casi no hacen suposiciones y a menudo utilizan todos los datos disponibles.
Objetivos del análisis exploratorio de datos
Los objetivos del análisis exploratorio de datos incluyen:
- descubrir modelos simples y eficientes con gran poder explicativo (es decir, modelos que puedan explicar los datos con parámetros mínimos);
- estimar parámetros y establecer la incertidumbre de dichas estimaciones;
- verificar suposiciones y lograr conclusiones confiables;
- identificar valores atípicos y anomalías;
- identificar las variables y factores importantes;
- maximizar el conocimiento de la estructura subyacente del conjunto de datos.
Un conjunto de datos bastante pesado es difícil de percibir. Se tiene que pasar por varias etapas de análisis exploratorio, y entre ellas habrá otras mutuamente excluyentes.
Pasos para el análisis de exploración
El proceso de análisis exploratorio de datos no es lo que se podría llamar “un camino sencillo”. Más bien, implica un proceso iterativo de cuestionar tus datos, la visualización y el análisis de datos, y la exploración de nuevas rutas. No existe una manera perfecta de trabajar con EDA, solo hay formas que funcionan y otras que no.
Los pasos que enumeramos a continuación son apenas una de las formas lógicas que puedes seguir para lograr un análisis exploratorio de datos eficaz:
1. Importación y limpieza de datos importados: el primer paso para cualquier análisis es importar los datos, limpiarlos y convertirlos al formato legible requerido.
2. Análisis univariado: es lógico comenzar el análisis mirando una variable a la vez, examinando la distribución de cada variable y las estadísticas resumidas.
3. Exploración de pares: el siguiente paso es determinar las relaciones entre pares de variables utilizando gráficos bivariados simples.
4. Análisis multivariado: al analizar variables en pares, es posible analizar las relaciones entre grupos más grandes para explorar e identificar relaciones más complejas.
5. Prueba y evaluación de hipótesis: en esta etapa se prueban las suposiciones hechas sobre el conjunto de datos y se hacen estimaciones con respecto a las variables.
6. Visualización: la visualización se utiliza durante la exploración y el análisis de datos, y para presentar los resultados de forma eficaz. Una de las herramientas preferidas para los analistas para la visualización de datos es Python.
Herramientas y técnicas de análisis exploratorio de datos
El análisis exploratorio de datos se basa principalmente en estadística. La ayuda adicional que proporcionan los gráficos estadísticos para descubrir secretos estructurales de patrones ha convertido al análisis de exploración en una herramienta indispensable en la búsqueda de nuevos conocimientos sobre los datos.
Visualización de datos: histogramas y diagramas de dispersión
La visualización de datos nos permite ver y comprender patrones, tendencias y relaciones en los datos a través de gráficos, diagramas y tablas. Un histograma es una representación gráfica de la distribución de datos en diferentes intervalos. Esto permite evaluar con qué frecuencia los valores caen dentro de ciertos rangos y qué picos tenemos en los datos.
Por otro lado, un diagrama de dispersión es un gráfico en el que cada punto representa una observación separada y muestra la relación entre dos variables. Esto ayuda a determinar si existe alguna dependencia o correlación entre ellos.
Este es un ejemplo de código Python para trazar un histograma y un diagrama de dispersión:

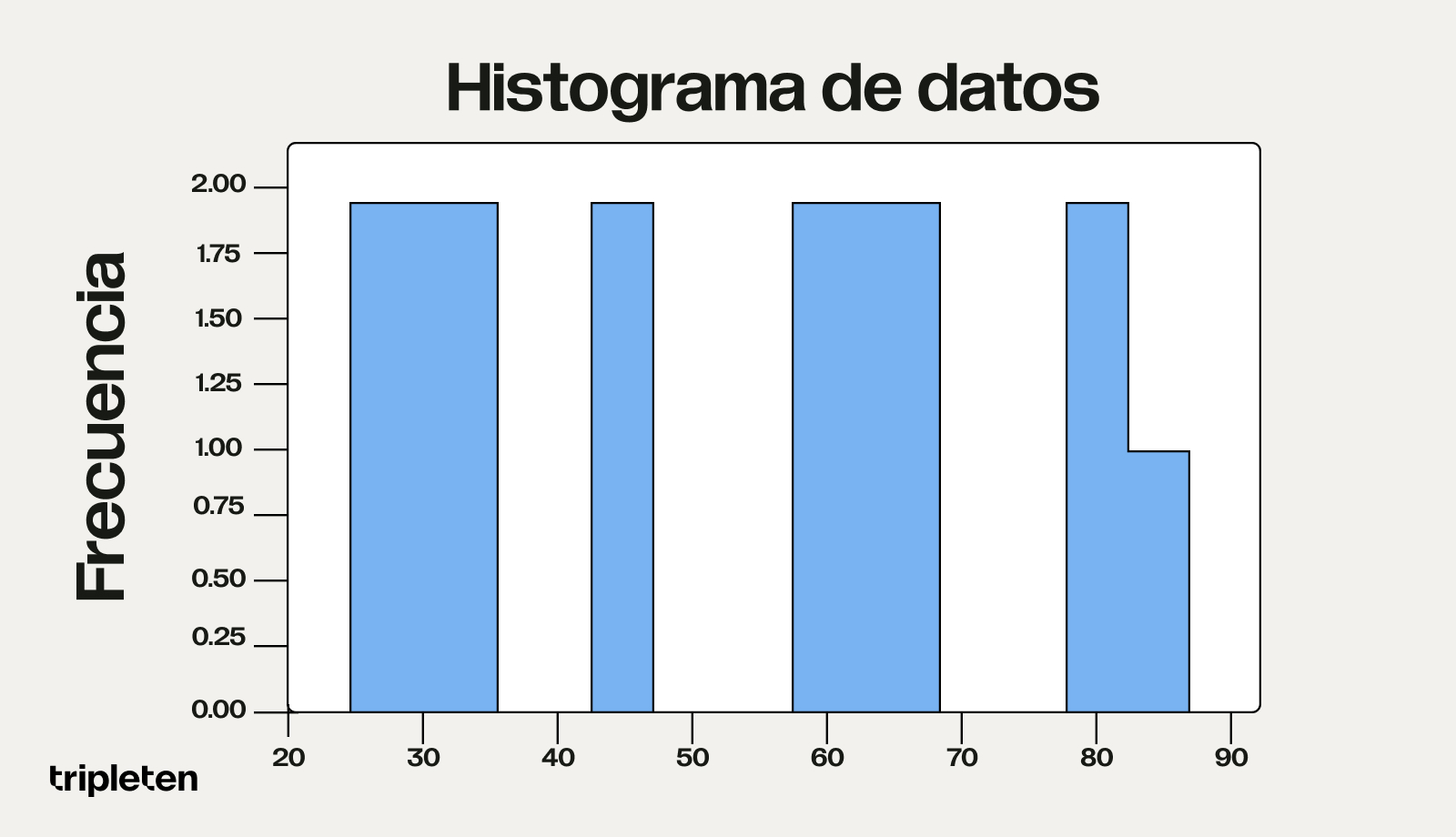
Resultado del código.
La visualización de datos en Python proporciona poderosas herramientas para explorar, analizar y visualizar información de un conjunto de datos. Aunque según la tarea y el tipo de datos, es posible utilizar gráficos y visualizaciones más complejos.
Análisis de correlación
El análisis de correlación ayuda a comprender qué variables están interrelacionadas y qué tan fuerte es esta relación. El coeficiente de correlación mide el grado de relación lineal entre dos variables.
• Correlación positiva: si una variable aumenta, la otra también aumenta. El coeficiente de correlación oscila entre 0 y 1.
• Correlación negativa: si una variable aumenta, la otra disminuye. El coeficiente de correlación oscila entre 0 y -1.
• Correlación cero: no hay relación lineal entre variables. El coeficiente de correlación es cercano a 0.
Análisis de valores atípicos y anomalías
El análisis de valores atípicos y anomalías es el proceso de identificar y examinar valores de datos que difieren significativamente de otras observaciones. Los valores atípicos y las anomalías surgen debido a errores de datos, eventos aleatorios o al indicar las características del fenómeno de estudio.
Transformación de datos
La transformación de datos es el proceso de cambiar la escala o distribución de variables para hacerlas más adecuadas para el análisis o modelados de datos. Este es un paso importante del EDA porque ayuda a suavizar las diferencias entre variables y crear datos más sólidos e interpretables.
La transformación de datos puede ser especialmente útil cuando se tienen variables con diferentes rangos de valores, lo que dificulta la interpretación de los resultados.
Todos estos métodos permiten obtener una comprensión más profunda de la estructura y las dependencias en los datos, lo que a su vez ayuda a tomar decisiones analíticas más informadas.
El análisis exploratorio de datos es una parte integral de un análisis de datos exitoso, y entre otras cosas permite al analista identificar tendencias interesantes y preparar datos para etapas posteriores del proyecto. En el curso de analista de datos de TripleTen no sólo aprenderás las mejores técnicas y herramientas para el análisis de datos, sino que el curso te prepara para tener una comprensión intuitiva de los datos, la estadística y su contexto, y utilizar estas habilidades en beneficio de las empresas. Únete hoy al curso de analista de datos y comienza a trabajar con análisis exploratorio de datos en cuestión de meses.
