¿Qué es el Machine Learning? Características, tipos y ejemplos de aprendizaje automático
Quizá te habrás dado cuenta de que en la actualidad, en cualquier evento de networking tecnológico de alto perfil, siempre se menciona el término Machine Learning, y se reafirma su importancia para el desarrollo tecnológico. Esto es por una buena razón: el Machine Learning no es otra cosa que una herramienta creada por los matemáticos para predecir el futuro ¡utilizando datos!
Desde algoritmos de aprendizaje profundo, hasta el desarrollo de redes neuronales, los pormenores del Machine Learning son fascinantes, y dominarlo podría ayudarte a iniciar una carrera exitosa en tech. Sigue leyendo para conocer a fondo qué es el Machine Learning, para qué sirve, y los beneficios de utilizarlo para predecir tendencias y comportamientos.
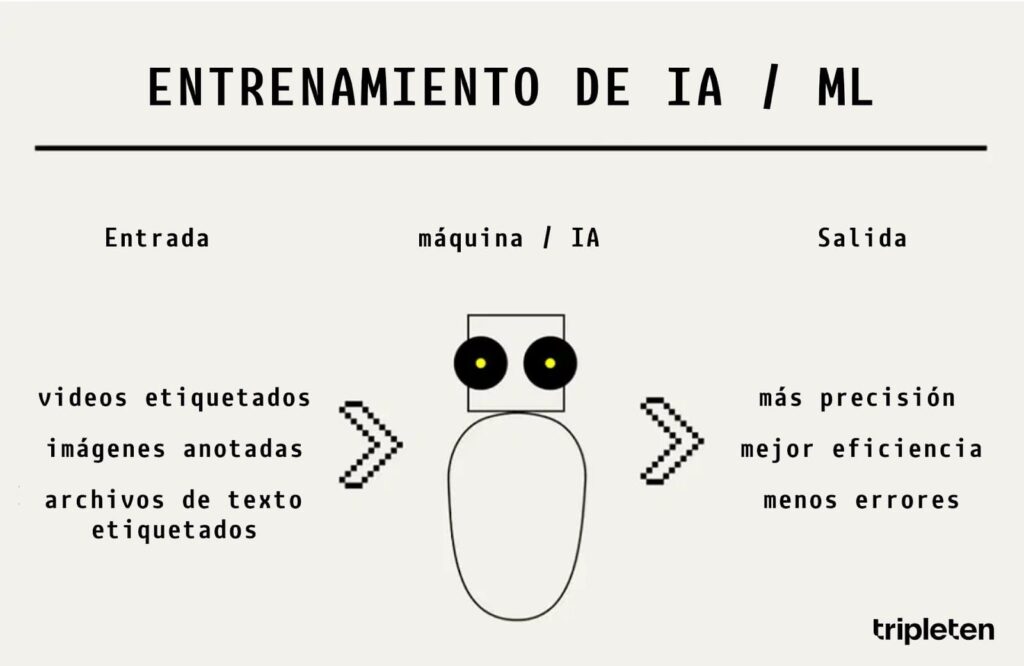
¿Qué es Machine Learning?
El aprendizaje automático, o Machine Learning (ML), es un proceso en el que un programa informático utiliza inteligencia artificial (IA) para encontrar patrones en los datos, y con base en ellos resolver problemas y tomar decisiones.
Este campo de la ciencia computacional se centra en la creación de programas que puedan tomar sus propias decisiones a partir de los datos. Esta independencia se logra al aplicar métodos matemáticos a los datos de entrenamiento; al trabajar con cualquier cantidad de datos y evaluarlos de forma imparcial, el ML resulta en una tecnología que enseña a una máquina a pensar y actuar como un ser humano.
Cuanto más detallada sea la información de entrada que recibe la inteligencia artificial, más preciso será el resultado. Después de este procesamiento, los programas pueden generar sus propios caminos de decisión que les permitan lograr objetivos más amplios con una mínima intervención humana.
¿Cómo y cuándo surge el aprendizaje automático?
El concepto de «aprendizaje automático» fue inventado por el investigador estadounidense, Arthur Samuel, quien en ese entonces trabajaba en IBM. En 1959 creó el primer programa de damas que podía jugar consigo mismo y aprender por sí solo. La dirección del juego dominada por Samuel comenzó a desarrollarse de manera muy activa. A finales de la década de los 80, un grupo de estudiantes de posgrado de la Universidad Carnegie Mellon diseñaron la máquina de ajedrez Chip Test, que se convirtió en el prototipo del legendario superordenador Deep Blue, que venció a Garry Kasparov en 1996.

Chip Test podía analizar hasta 50 mil movimientos por segundo.
El partido con Kasparov fue un hito en el desarrollo de aplicaciones del Machine Learning. Antes del Deep Blue, los algoritmos no eran rival para los humanos; les faltaba intuición e improvisación. Por supuesto, IBM, que creó Deep Blue, no dotó a la máquina de una intuición real, pero creo una computadora con una potencia que le permitía calcular aún más opciones.
Poco después, comenzó una nueva revolución en la historia de la IA y el Machine Learning. En 2011, Google fundó Google Brain, una división dedicada a proyectos de IA, y tres años después, Amazon y Microsoft lanzaron sus propias plataformas de ML, y Facebook presentó DeepFace, un algoritmo capaz de reconocer rostros humanos.
¿Cómo funciona el aprendizaje automático y por qué es tan importante?
Cuando concretamos una cita médica a través de un chatbot, o pedimos a Siri o Alexa que reproduzca una canción, lo que hace posible esta acción —que no notamos porque sucede tras bambalinas y en cuestión de mili segundos— es producto de un proceso sumamente complejo que incluye elementos de Machine Learning.
El modelo que utiliza el Machine Learning es similar a una caja negra: toma datos como entrada (la condición del problema) y produce una determinada respuesta como salida.
Pero la caja negra tiene muchos parámetros adicionales, que influyen en cómo se procesarán exactamente los datos. Las técnicas de Machine Learning y los tipos de tareas influyen en cómo se configuran estos parámetros.
El algoritmo de ML no tiene una respuesta determinada a la que llegar, sino que construye un modelo que responda a la pregunta planteada. En este sentido, el objetivo de esta rama de la inteligencia artificial es enseñar al modelo a encontrar una solución por sí mismo para aumentar la precisión y la velocidad de las decisiones.
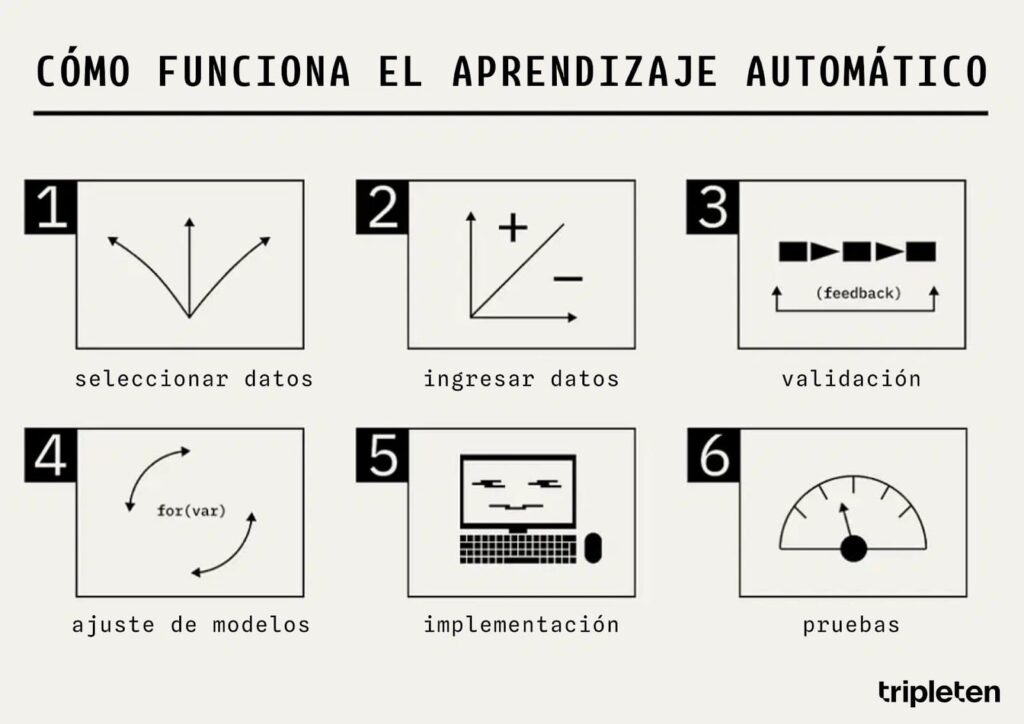
Así es como se ve un esquema de Machine Learning.
Cabe destacar que la tecnología de Machine Learning no es lo mismo que la programación. El programador crea un algoritmo para la máquina, que prescribe una secuencia clara de acciones que conducirán al resultado deseado. El especialista en ML que entrena el modelo no escribe un programa para la máquina; su trabajo consiste en transmitir datos e intenta explicar lo que quiere obtener como resultado.
Casos de uso del Machine Learning
El proceso que siguen los sistemas de Machine Learning es:
1. recibir datos;
2. clasificarlos;
3. hacer una predicción o conclusión precisa con base en ellos.
Hoy en día, esta capacidad de la IA para recordar información, analizar y predecir datos se utiliza para casi todo. A continuación te dejamos algunos ejemplos de cómo y dónde se utilizan los algoritmos de Machine Learning:
Banca. Algunos programas de calificación hoy en día son capaces de resolver un problema gracias a que procesan una gran cantidad de cuestionarios crediticios. Para este caso, los especialistas crean un modelo que calcula automáticamente la calificación crediticia, evalúa la solvencia del cliente y determina si aprueba o rechaza un préstamo.
Marketing. Cuando Spotify te sugiere una lista de reproducción o crea una lista personalizada para ti, se trata de una tarea de recomendación que utiliza Machine Learning. Otro ejemplo son las tiendas online en las que, mediante el ML, los algoritmos aprenden a relacionar a un cliente con su cesta virtual y a seguir el movimiento de los productos en los diferentes departamentos.
Medicina. Uno de los ejemplos más destacados es el descubrimiento realizado por el algoritmo AlphaFold en 2020, el cual modeló el proceso de plegamiento de proteínas y resolvió así uno de los problemas bioquímicos más difíciles de la medicina: prevenir el desarrollo de infecciones, enfermedades cognitivas y neurodegenerativas (como el Parkinson o el Alzheimer).
Agricultura. Con la ayuda del ML, se han creado modelos que pueden analizar la composición del suelo, calcular la cantidad necesaria de fertilizantes, predecir el rendimiento de los cultivos, e incluso predecir la producción de ciertos productos animales y vegetales.
Ventas. Digamos que un comerciante vende helados en un parque durante la semana. Al final de cada semana, recopila datos para optimizar sus ventas: cuánto helado se vendió y cómo estuvo el clima cada día. A partir de esta información, la IA analiza cómo subieron o bajaron las ventas en función de la temperatura, y de esta forma utiliza el pronóstico del tiempo para calcular cuánto helado necesita el proveedor para la siguiente semana.
Seguridad. Uno de los logros más importantes de la IA es el sistema de reconocimiento facial para la protección de la privacidad y la seguridad. Gracias a modelos de ML, la IA es capaz de identificar a una persona por parámetros externos, por ejemplo la forma de la nariz y el color de ojos.
¿Qué métodos de entrenamiento existen para el aprendizaje automático y cuáles son sus características?
Existen tres métodos de entrenamiento para el Machine Learning, y cada uno tiene sus propios parámetros para procesar la información.
1. Aprendizaje supervisado: utilizado para clasificación y regresión
La clasificación es una tarea en la que es necesario asignar una clase a un objeto (gato, perro, coche, casa, etc.), mientras que la regresión es un problema en el que es necesario asignar un valor numérico —por ejemplo, el número de personas en el aeropuerto en función del día de la semana—.
Para este modelo de ML, el especialista utiliza datos etiquetados para entrenar el modelo; esto significa que, para cada ejemplo, ya existe una respuesta correcta. El trabajo del algoritmo aquí consiste en comprender por qué tal respuesta es la correcta.
Un ejemplo sería enseñar a un algoritmo a reconocer vehículos en las calles. El entrenamiento consiste en utilizar muchas fotografías en las que todas las zonas, incluidos los autos, estén marcadas con rectángulos; el modelo deberá encontrar las relaciones entre las zonas de los rectángulos y establecer que contienen el mismo objeto: un automóvil.

La detección de automóviles mediante visión por computadora y Machine Learning supervisado se utiliza en el diseño de vehículos autónomos.
2. Aprendizaje no supervisado: adecuado para agrupaciones de datos
El clustering, o agrupación, es una técnica de aprendizaje no supervisado que consiste en agrupar elementos a través de la extracción de características. En este método de entrenamiento, el modelo recibe datos sin etiquetar, es decir sin evaluación, e intenta identificar patrones por sí mismo.
Un caso de aplicación de este método sería analizar a todas las personas usuarias de una tienda online para clasificarlas por comportamiento, e identificar a aquellas que compran con mayor frecuencia ciertos productos. Por ejemplo, si un cliente compra juguetes, pañales y jabón para bebé todos los meses, es lógico inferir que esta persona tiene infantes, y que comprará estos productos aproximadamente cada 30 días.
3. Aprendizaje por refuerzo: óptimo para crear bots
En este modelo de Machine Learning, el algoritmo se entrena a sí mismo mediante muchos experimentos de prueba y error, ya que la tarea consiste en seleccionar una respuesta adecuada en función de las acciones del usuario. El aprendizaje por refuerzo se produce cuando el algoritmo interactúa de forma continua con el entorno, en lugar de depender de los datos de entrenamiento.
El ejemplo más popular son los bots para jugar a las damas o al ajedrez, ya que el algoritmo intentará tomar una decisión en función de las acciones del otro jugador.
Modelos y algoritmos de Machine Learning
Un algoritmo de Machine Learning es un método matemático diseñado para enseñar a una computadora a pensar y actuar como una persona, solo que con mayor precisión. Los algoritmos de ML suelen derivarse de la estadística, el cálculo y el álgebra lineal; el modelo se basa en datos sobre el objeto.
Veamos ahora ejemplos de modelos de Machine Learning. Cada uno de ellos se utiliza para diferentes propósitos, es decir, para resolver el mismo problema de diferentes maneras.
Aprendizaje supervisado
• Regresión lineal. La regresión lineal se utiliza para identificar relaciones entre la variable de interés y las entradas, y predecir sus valores en función de los valores de las variables de entrada.
• Regresión logística. La regresión logística se utiliza para determinar si una entrada pertenece a un determinado grupo o no.
• Árboles de decisión. Los árboles de decisión también son clasificadores que se utilizan para determinar en qué categoría cae una entrada al recorrer las hojas y los nodos de un árbol.
• SVM. El SVM, o máquina de vectores de soporte, crea coordenadas para cada objeto en un espacio n-dimensional y utiliza un hiperplano para agrupar objetos por características comunes.
• Naive Bayes. Naive Bayes es un tipo de algoritmo que supone independencia entre variables y utiliza la probabilidad para clasificar objetos en función de características.
• kNN. La técnica k Nearest Neighbors implica agrupar los objetos más cercanos en un conjunto de datos etiquetado y encontrar las características más frecuentes o promedio entre los objetos.
• Modelo de bosque aleatorio. El bosque aleatorio es una colección de muchos árboles de decisión de subconjuntos aleatorios de datos, lo que da como resultado una combinación de árboles que puede ser más precisa en la predicción que un solo árbol de decisión.
• Algoritmos de refuerzo. Los algoritmos de refuerzo, como Gradient Boosting Machine, XGBoost y LightGBM, utilizan el aprendizaje conjunto; combinan las predicciones de varios algoritmos (como árboles de decisión) y toman en cuenta el error del algoritmo anterior.
• Redes neuronales artificiales. Como su nombre indica, las redes neuronales artificiales simulan el funcionamiento del cerebro humano: consta de capas de nodos (neuronas artificiales) interconectados, donde cada nodo es capaz de aprender a hacer coincidir los datos de entrada con los datos de salida.
Aprendizaje semisupervisado
• K-Means. El algoritmo K-Means encuentra similitudes entre objetos y los agrupa en K grupos diferentes.
• Agrupamiento jerárquico. La agrupación jerárquica crea un árbol de conglomerados anidados sin tener que especificar el número de conglomerados.
Aplicaciones de Machine Learning
El Machine Learning permite resolver problemas en cualquier industria, pero solo se aplicará bien en los casos en que el problema contenga una cantidad acumulada de datos relevantes.
Machine Learning como rama de la ciencia de datos
No olvidemos que el Machine Learning es una rama de la ciencia de datos. Esta tecnología es esencial para procesar volúmenes masivos de datos y detectar patrones útiles. Herramientas como modelos predictivos y algoritmos de clasificación permiten a las computadoras anticipar tendencias de mercado y detectar fraudes financieros, entre otros beneficios.
Machine Learning empresarial
El Machine Learning se utiliza para analizar grandes volúmenes de datos, mejorar la toma de decisiones y personalizar experiencias. Un ejemplo de aplicación del ML para este propósito son los sistemas de recomendación en plataformas como Netflix o Amazon. También optimiza los procesos logísticos, como en la industria de transporte o gestión de inventarios.
Aprendizaje profundo (Deep Learning)
Este subcampo del Machine Learning emplea redes neuronales para resolver problemas complejos, como el reconocimiento de imágenes, procesamiento del lenguaje natural y conducción autónoma. Empresas como Tesla y Google hoy en día están a la vanguardia de estas aplicaciones.
No obstante, aunque el aprendizaje profundo es una subsección del aprendizaje automático, su principio operativo es diferente. El Machine Learning requiere que las características de los datos en las que debe centrarse el algoritmo las especifique una persona, mientras que la red neuronal de aprendizaje profundo es capaz de encontrarlas sin que se le solicite.
Beneficios del Machine Learning
Machine Learning en las empresas para mejorar procesos
Los algoritmos de Machine Learning pueden identificar ineficiencias que los humanos podrían pasar por alto, lo que permite optimizar recursos y aumentar la productividad.
Imagina una joven emprendedora llamada Elena que es dueña de un negocio de comercio electrónico. A medida que crece su negocio, se enfrenta a problemas como la gestión de inventarios, el servicio al cliente y la personalización de recomendaciones.
Pero Elena decide integrar sistemas de ML a su negocio, y gracias a que implementa un sistema de recomendaciones y un chatbot que maneja el 80% de las consultas frecuentes, no solo aumenta sus ventas en un 30%, sino que logra liberar a su equipo para atender casos más complejos.
Minería de datos y análisis predictivo que reduce la intervención humana
Al ser una gran herramienta para automatizar tareas repetitivas, el uso de algoritmos de Machine Learning permite a los especialistas liberar tiempo para actividades más creativas y estratégicas. El mejor ejemplo de esto son los chatbots que, como en el caso de Elena, al estar diseñados para responder las preguntas más frecuentes y manejar consultas básicas, liberan horas de trabajo humano y mejoran la experiencia del cliente.
Predicciones y automatización de tareas
Desde el uso de software de reconocimiento facial en sistemas de ciberseguridad, hasta la clasificación y la extracción de datos personales para hacer predicciones de mercado, el Machine Learning ofrece un punto medio en operaciones que requieren velocidad y precisión, además de que, desde una perspectiva global, sirve para mejorar el mundo, los procesos y los fenómenos que nos rodean.
Los especialistas en ciencia de datos saben que cualquier sistema automático siempre se puede mejorar, lo que resulta sumamente motivador para seguir adelante y desarrollarse en la profesión.
Desafíos del aprendizaje automático: por qué SÍ entrenar máquinas con IA
Limitaciones técnicas y conjuntos de datos
Para entrenar una máquina, primero debes recopilar datos sobre los cuales la computadora tomará decisiones —puede ser cualquier información relacionada con el objeto modelado, ya sean números, imágenes o texto—. Pero, en este sentido, la principal tarea del especialista que entrena máquinas es comprender qué información se requiere para el análisis de datos (y cuál no).
Algunas de las limitaciones técnicas a las que se enfrentan los especialistas que trabajan con Machine Learning son:
• Modelos sobreajustados que funcionan bien con datos de entrenamiento, pero no generalizan a datos nuevos.
• Costos computacionales elevados para entrenar redes neuronales profundas.
• Dependencia de grandes cantidades de datos etiquetados, que a menudo no están disponibles.
La ventaja está en que los modelos de Machine Learning mejoran con los datos. Esto significa que, a medida que se recopilan más datos, los sistemas pueden mejorar su precisión y adaptarse a cambios en el entorno, lo que es crucial para industrias dinámicas como la tecnología financiera o el comercio electrónico.
Problemas éticos y de privacidad
Imagina que tienes un negocio en el que utilizas el ML para mejorar la experiencia de tus clientes, pero un día alguien te escribe para preguntarte cómo se usan sus datos. ¿Conoces las implicaciones éticas de recopilar tanta información y de tal índole?
El Machine Learning plantea importantes desafíos éticos y de privacidad debido a su dependencia de grandes volúmenes de datos para entrenar modelos. No obstante, este desafío subraya la importancia de auditar y supervisar los algoritmos para garantizar resultados justos e incluyentes—un ejemplo de esto es el GDPR en Europa, una legislación que busca abordar este problema al exigir prácticas de recopilación y almacenamiento más estrictas.
A pesar de las dificultades técnicas y éticas, el Machine Learning continúa siendo una herramienta esencial para la evolución en múltiples industrias. Estas son solo algunas razones clave para su adopción:
1. Resolución de problemas complejos. El ML permite abordar problemas que serían imposibles de resolver de manera manual o con métodos tradicionales.
2. Eficiencia y escalabilidad. Los algoritmos de ML pueden analizar datos y encontrar diferencias en la información a una velocidad y escala que los humanos no pueden igualar. Esto no solo mejora la eficiencia, sino que hace posible tomar decisiones en tiempo real.
3. Transformación y creación de valor. Más allá de la optimización de procesos, el ML impulsa la creación de nuevos modelos de negocio y servicios. Desde asistentes virtuales con reconocimiento de voz que mejoran la productividad personal, hasta aplicaciones en energías renovables que optimizan el uso de recursos, el ML nos ayuda a moldear un futuro más innovador y sostenible.
Si bien el Machine Learning es una herramienta poderosa, su implementación requiere un enfoque equilibrado que considere tanto los beneficios como los riesgos. ¿La posible solución? Invertir no solo en tecnología, sino en educación y regulación para garantizar que estas herramientas se utilicen de manera responsable, ética y sostenible.
Entrenamiento y recursos
La implementación de sistemas de Machine Learning generalmente la lleva a cabo un especialista en ciencia de datos, el cual procesa datos y construye modelos para inteligencia artificial.
Aunque no es necesario ser un experto en alta tecnología y programación para conseguir un trabajo de Machine Learning, sí necesitas algunas habilidades:
• saber estructurar la información;
• pensar lógicamente y saber realizar análisis estructural;
• conocer el lenguaje de programación Python, ya que en él están escritos los algoritmos para el procesamiento de datos;
• conocer Java y Scala, pues en ellos están escritas herramientas para el procesamiento de datos;
• dominar SQL, un lenguaje de consulta que se utiliza para obtener información de una base de datos;
• poder utilizar herramientas para trabajar con bases de datos, por ejemplo, el ecosistema Hadoop para crear lagos de datos.
La buena noticia es que puedes adquirir estas habilidades en poco tiempo (¡solo 9 meses!) en nuestro bootcamp para científico de datos. Aquí no solo podrás adquirir los conocimientos para maquinas aplicaciones de Machine Learning, sino que recibirás orientación para dar tus primeros pasos en tech y conseguir un trabajo como especialista de ML. Atrévete a explorar nuestros bootcamps mejor evaluados y prepárate para entrar en tech en menos de un año.
